什么是压力测试
当我们开发完一个Web系统,实现了需求中的所有功能,此时还不能马上将其上线。我们必须对这个系统进行充分的,全面的测试,最大程度地确保它不会出错。压力测试就是这些测试的一种。压力测试的目的是为系统模拟一个现实的访问场景,建立一堆线程去并发地访问系统,了解这个Web系统能支持多大的并发量,或者说支持多少用户同时在线而不会崩溃。我们通过调整并发的线程数,访问时间等参数,去了解在一定的硬件配置下,我们的系统能支持多少线程在多少时间内同时访问。在确定了这些测试数据以后,我们便对这个Web系统的性能有一个比较客观全面的了解,从而可以更好地寻求优化的方案。
关于JMeter
JMeter是用java实现的开源的压力测试工具,功能强大,使用简单,在压力测试中占据极其重要的地位。这一讲就以JMeter对一个简单的微博系统进行压力测试的实例入手,介绍一下JMeter最基本的一些知识,看看JMeter是怎么对HTTP request进行测试的。虽然是以实例的形式去介绍,但涉及的都是JMeter最基本的内容,更深入的学习还需不断参考JMeter官方文档。
微博系统测试任务
- 登录
- 对某用户进行关注
- 对某用户取消关注
- 发一条微博
- 查找自己的微博列表
- 对刚刚发的微博添加一条评论
- 查找该微博的评论列表
- 删除刚刚添加的评论
- 删除刚刚发的微博
- 登出
以上测试基本涵盖了我们这个微博系统的所有功能。我们这个微博系统是已经实现好的,后台采用简单的servlet实现。我们只需要根据这个微博系统不同servlet的输入参数和返回内容进行测试即可。其他任何Web系统的压力测试也可以套用或者参考。
建立线程组
在官网上下载了JMeter以后,便可以运行jmeter.sh,打开JMeter的图形操作界面。此时,我们只看到一个空白的Test Plan,可以修改Test Plan的名字。
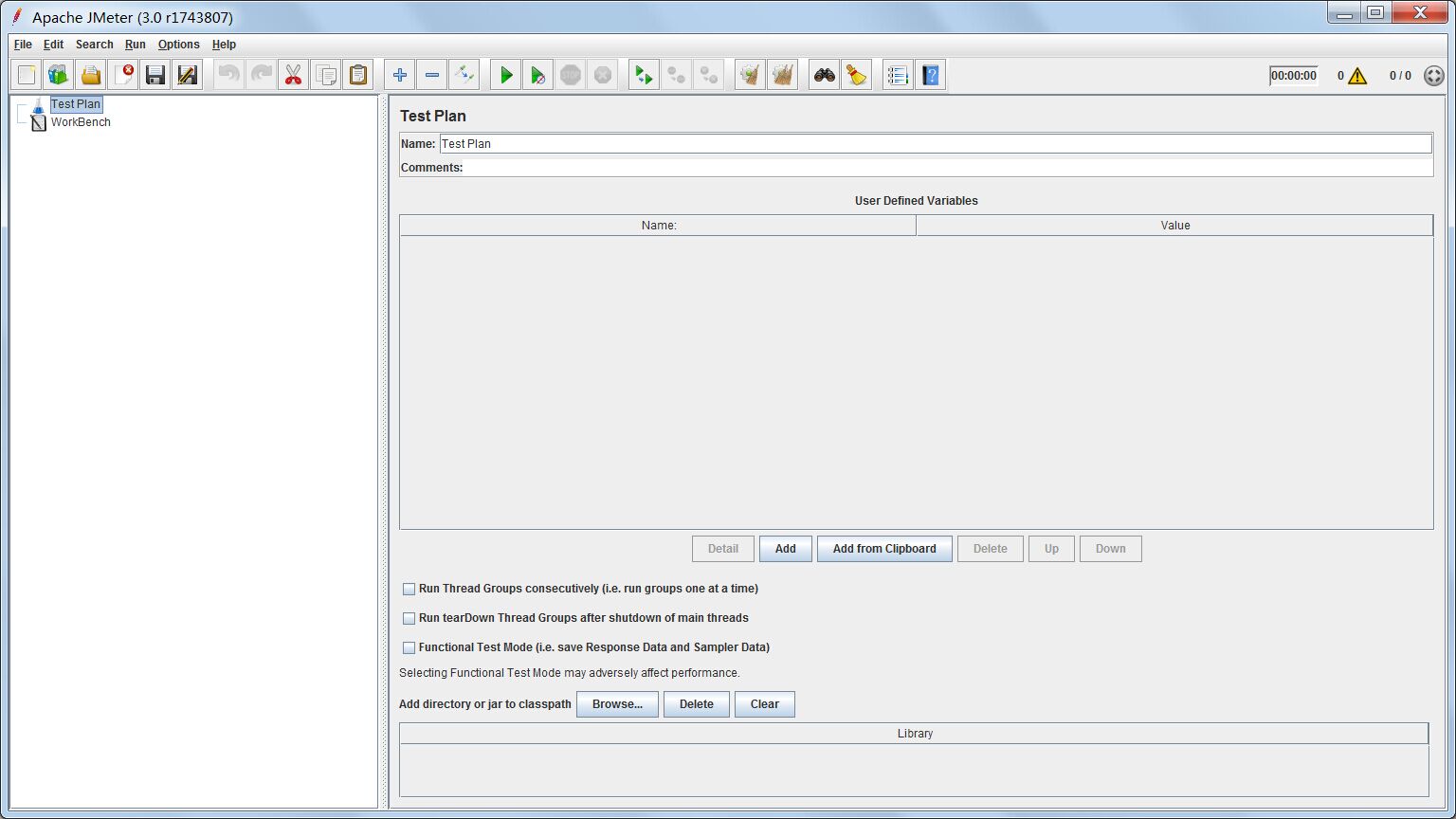
右键点击左边栏的Test Plan,可以新建线程组。线程组就是我们配置线程,模拟并发访问的地方。
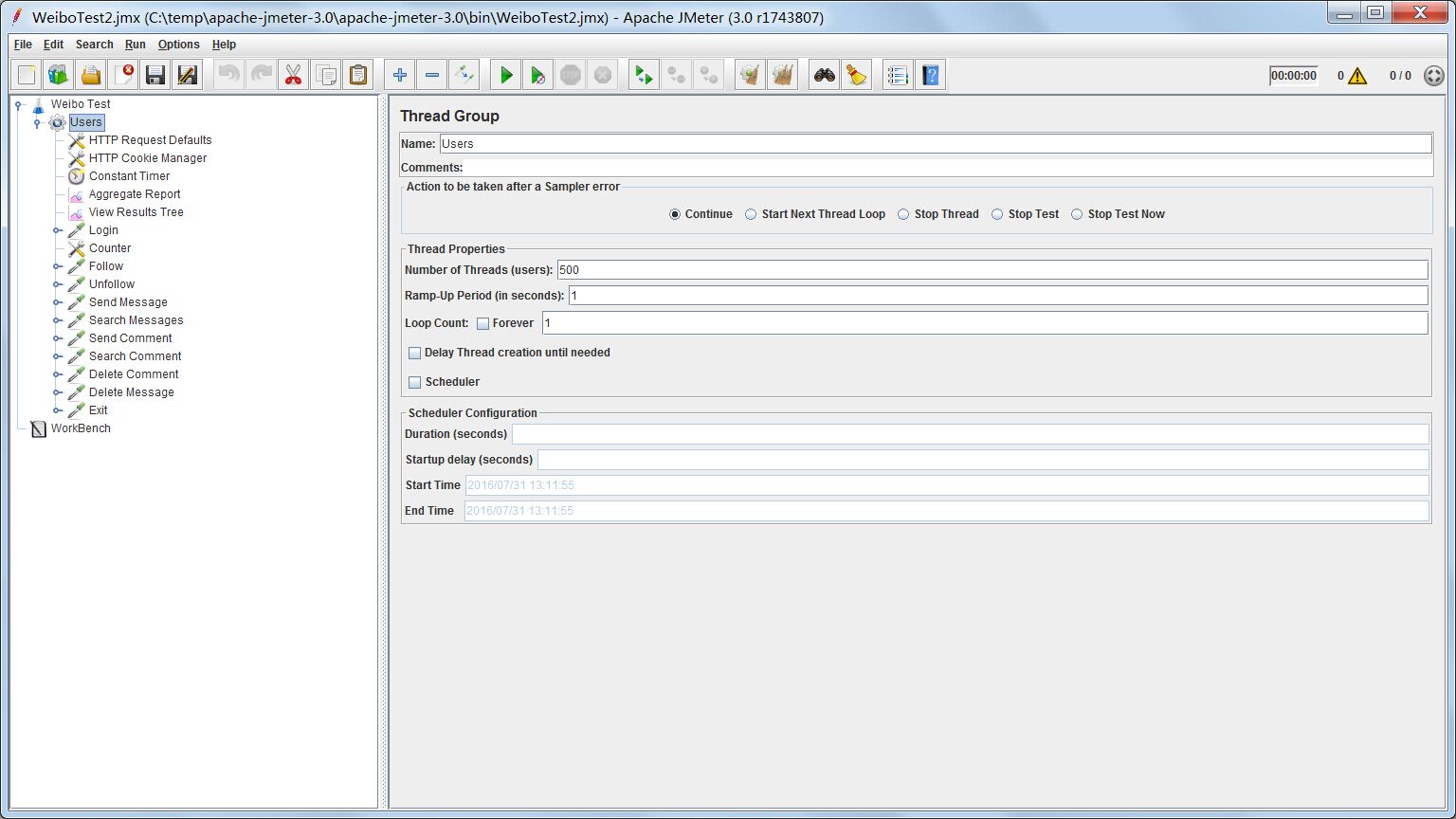
- Number of Threads是一共要启的线程数。
- Ramp-up Period是用多少时间启动线程组。假如Number of Threads我们填了10,Ramp-up Period填了100,那么每10秒会启动一个线程,100秒会启动完所有线程。
- Loop Count是循环运行线程组的次数,默认运行一次,不循环。
在测试过程中,我们要不断修改上面这3个参数,尤其是前两个。我们需要试出合适的参数,启动线程的频率不能太快也不能太慢,太慢往往所有线程都运行成功,且最后一个线程启动时前面的线程有些已经结束,达不到测试的效果,太快则产生一堆错误。使得系统刚好出错的参数配置,就是性能的临界点。
基本配置
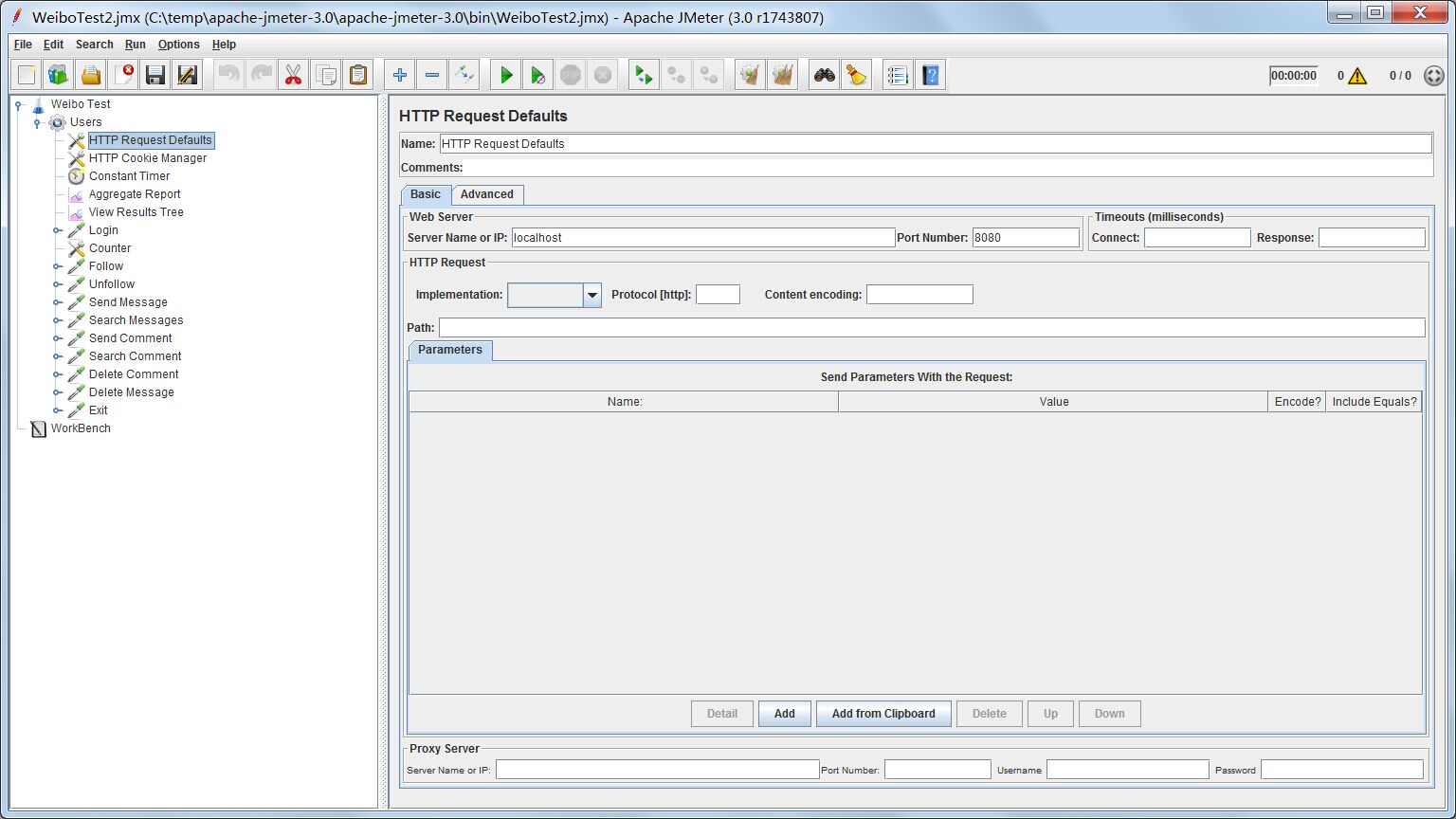
HTTP Request Defaults
在线程组下建立HTTP Request Defaults这个配置元素。由于我们需要测试的微博系统其域名或IP地址是固定的,访问的端口号也是固定的。我们进行的所有HTTP Request测试都要填写相同的IP和端口号,十分麻烦,修改也要全部修改。HTTP Request Defaults就是让我们在一个地方填写好基本配置信息,在同一作用域下的所有HTTP Request测试都能应用这个配置。假设我们的微博系统是建立在本机的,端口号采用Tomcat默认的8080,则配置如下:
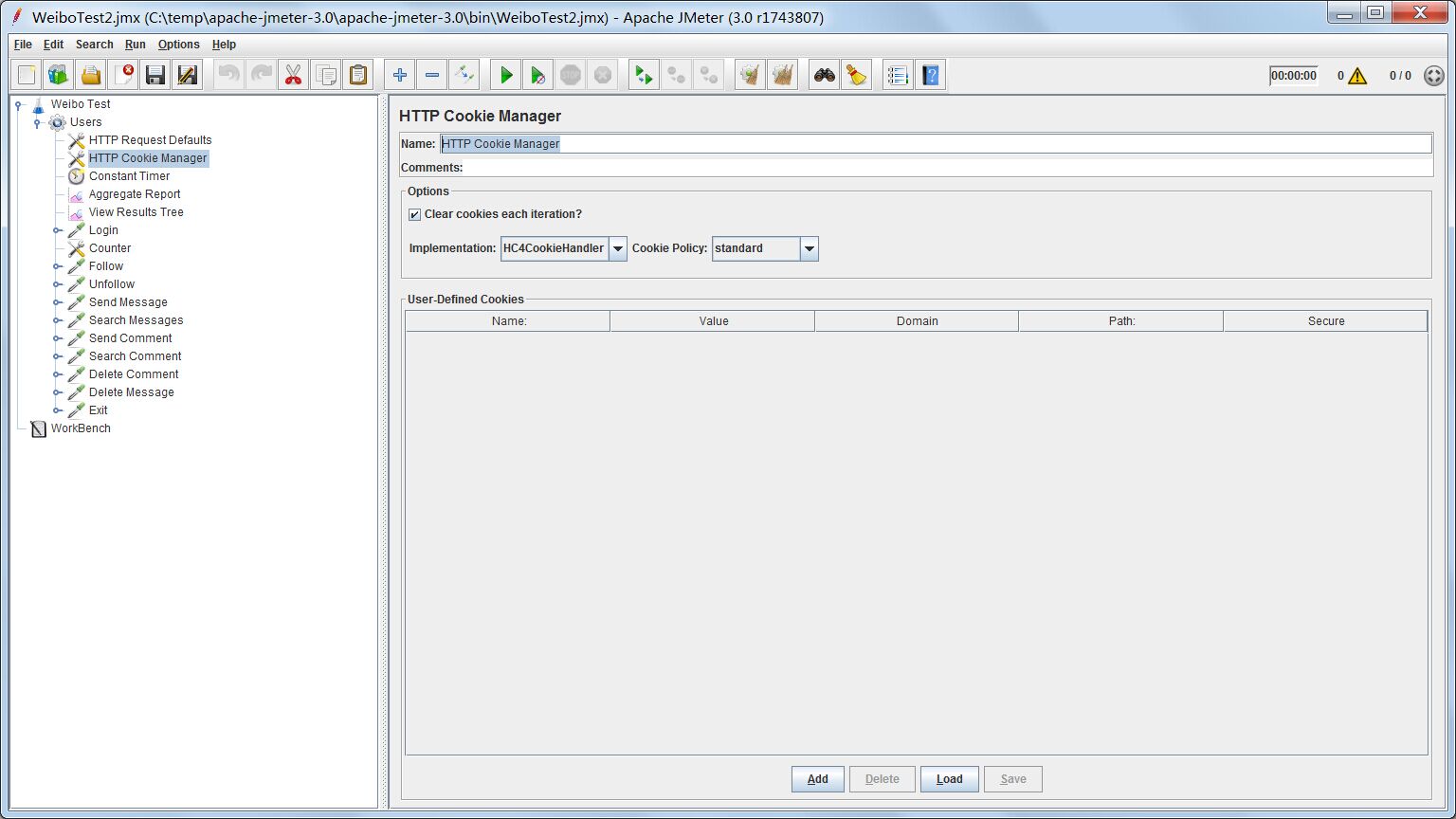
HTTP Cookie Manager
很多网站需要用cookie记录用户的登录信息,在用户登录以后,之后的Http Request便带有登录过的cookie信息,进而访问网站资源。没有携带这些cookie数据的需要重新登录。在进行压力测试,模拟并发访问时,登录后的后续测试都需要携带相应的cookie才能正常进行测试。HTTP Cookie Manager便可以让我们的所有Http Request都共用同样的cookie。
Constant Timer
用户在实际访问网站时,每一个操作之间往往有一定的时间间隔,不可能不间断地进行。为了真实地模拟用户行为,我们需要一个延时的功能,让每个线程启动之间有一定的时延。这个需求Constant Timer可以满足。
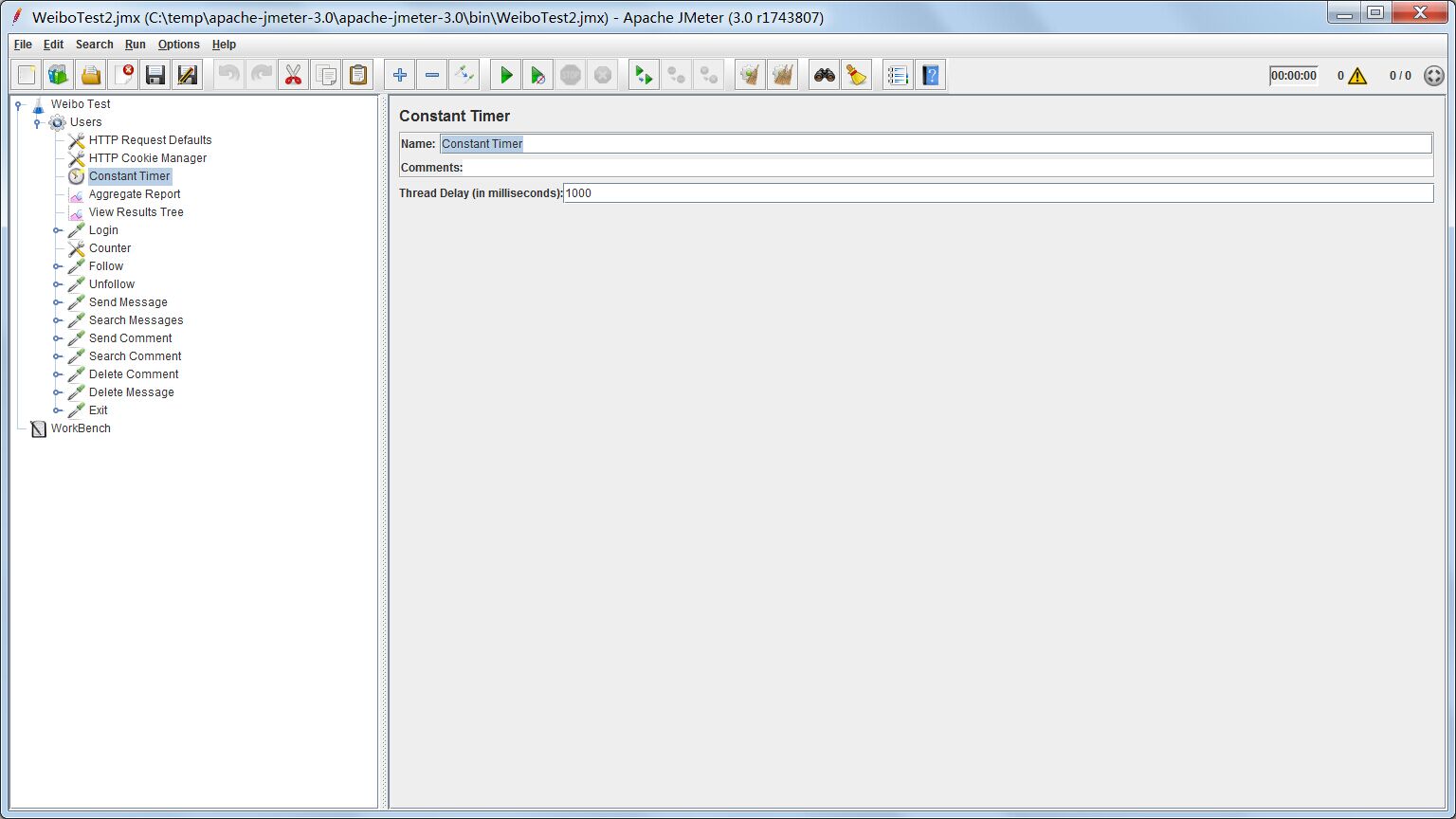
如图所示,Thread Delay便是以毫秒为单位的固定时延数。除了固定时延,还有其他的计时器可以实现时延效果。
测试报告
我们可以用多种形式来呈现测试结果。下面介绍比较常用的两种,结果树和聚合报告。
结果树
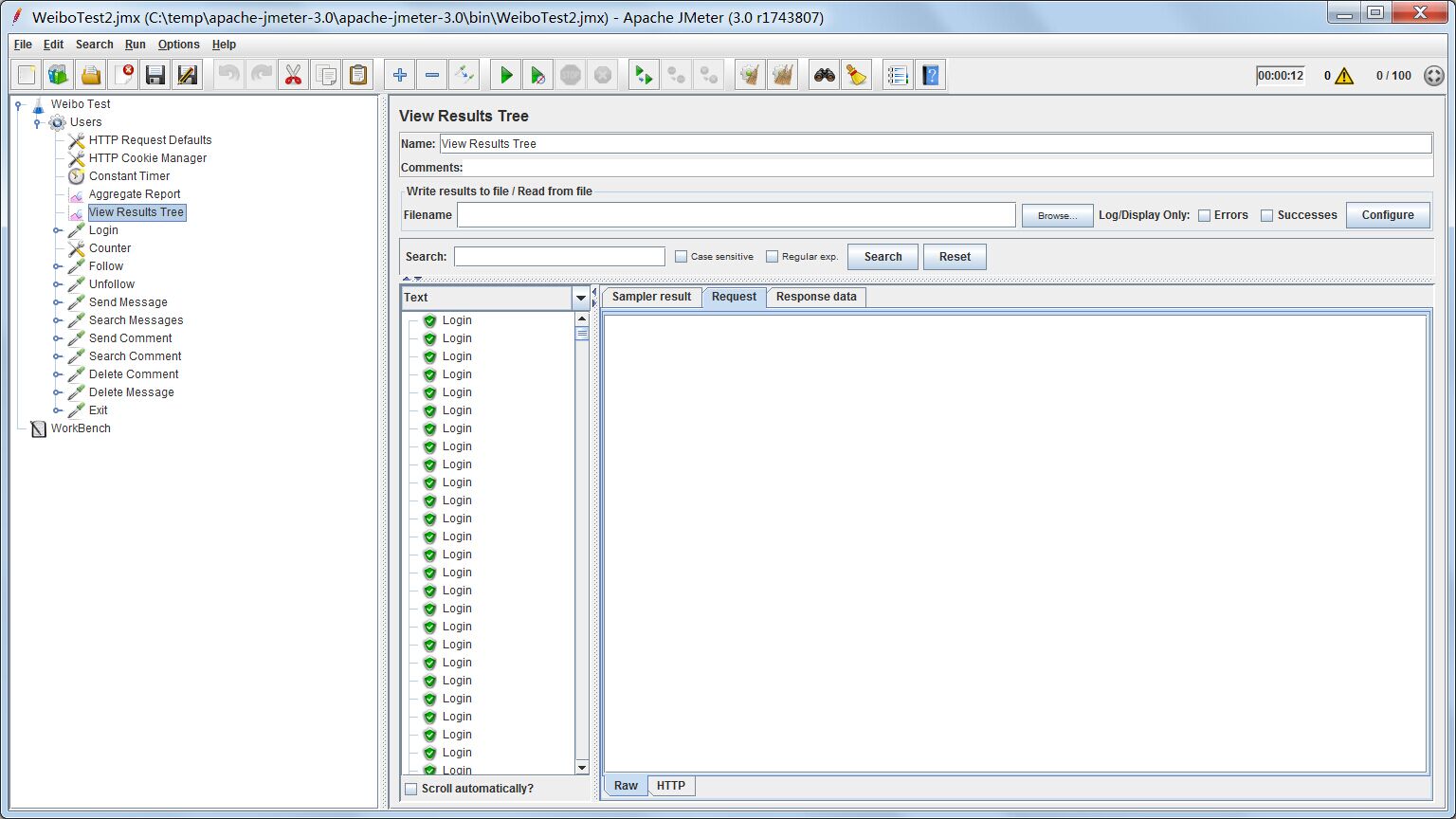
结果树能顺序地把每一个线程的每个测试的结果列出来,绿色代表成功,红色代表失败,并且可以查看每个测试的具体信息,例如request和response的具体内容,可以知道哪里出错。
聚合报告
结果树能看到具体的测试信息,但缺乏整体的概览。我们希望知道进行了多少测试,失败率多少,平均耗时是多少,聚合报告便能很清晰地提供给我们这些信息。
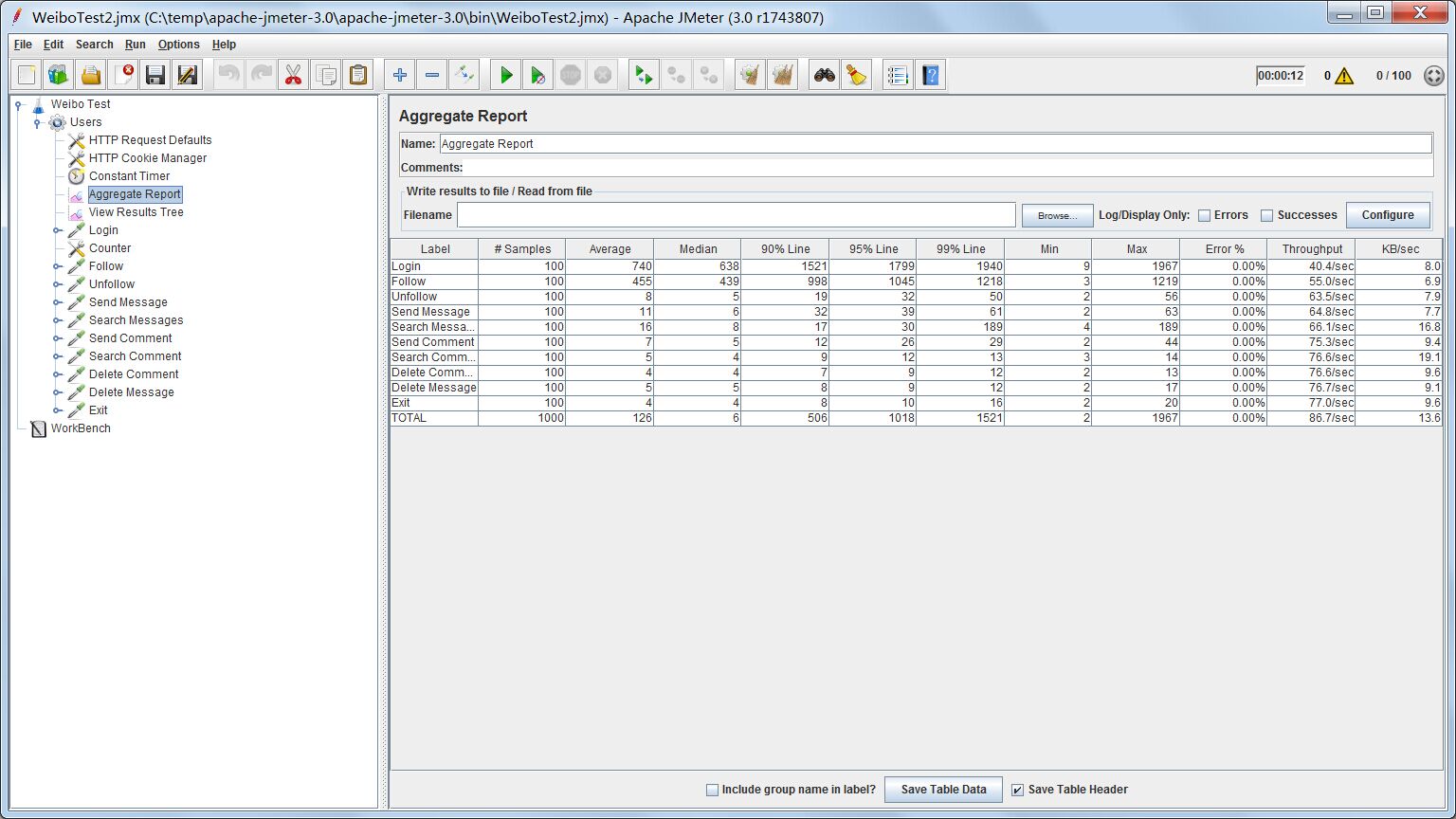
我们可以把结果树和聚合报告都添加进线程组内,结合两个测试报告去分析我们的结果。
断言
断言用于定义一些判断测试请求是否正确的规则。
默认情况下,如果http response的状态码是200就表示测试正确。但实际情况要复杂很多,response返回200只能表示正常访问到资源,很有可能相应的业务逻辑不正确。下面介绍两种比较常用的判断请求是否正确的手段,都是用断言实现的,分别是Response Assertion和Duration Assertion。
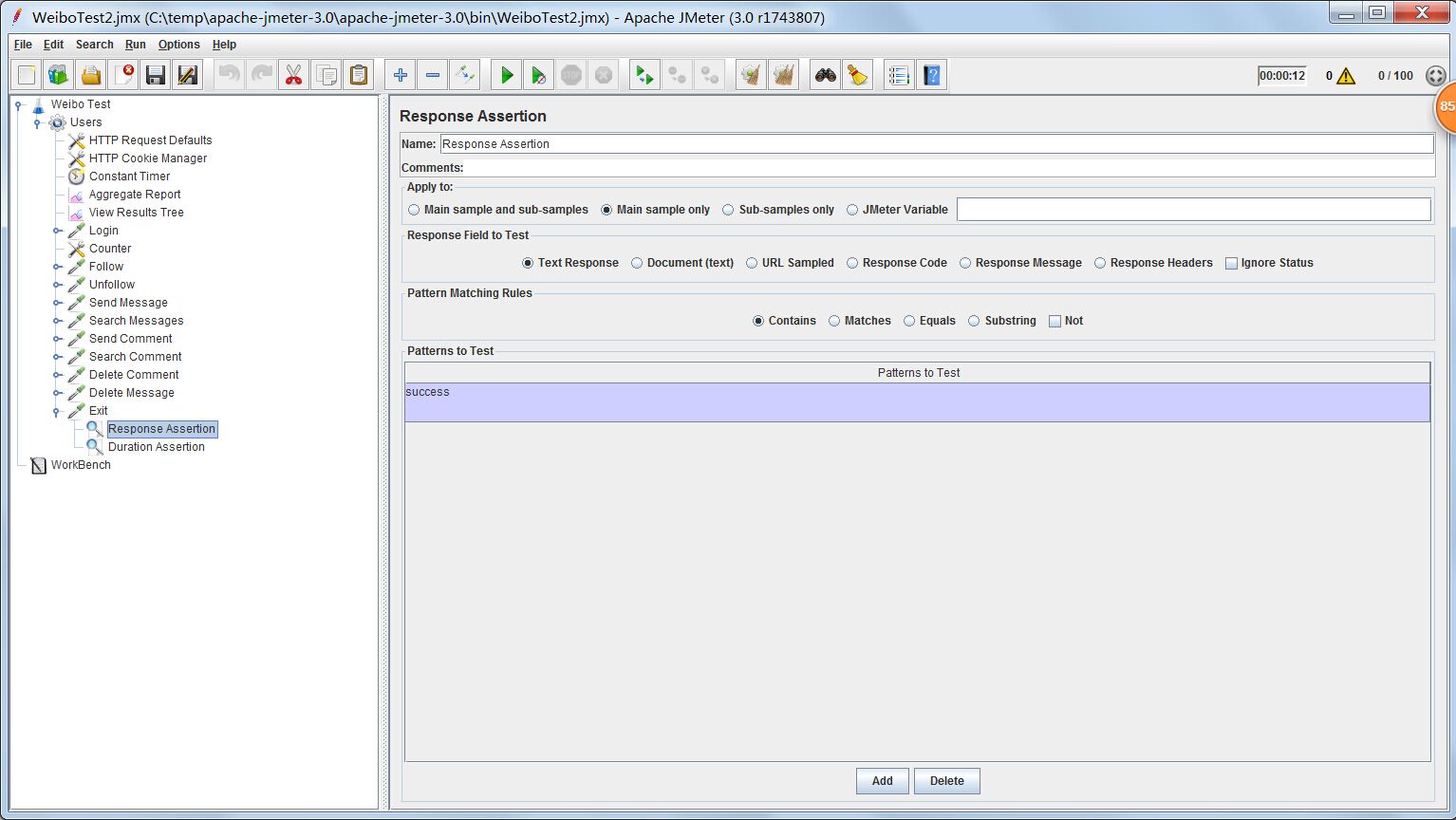
Response Assertion
一般情况下,对于每一个http request,相同的输入参数应该会让http response返回相同的内容。这些内容可能是html页面,也可能是一些返回数据。通过添加Response Assertion到相应的测试Sampler上,如果response的返回包含某些内容就说明正确,不包含就说明失败。
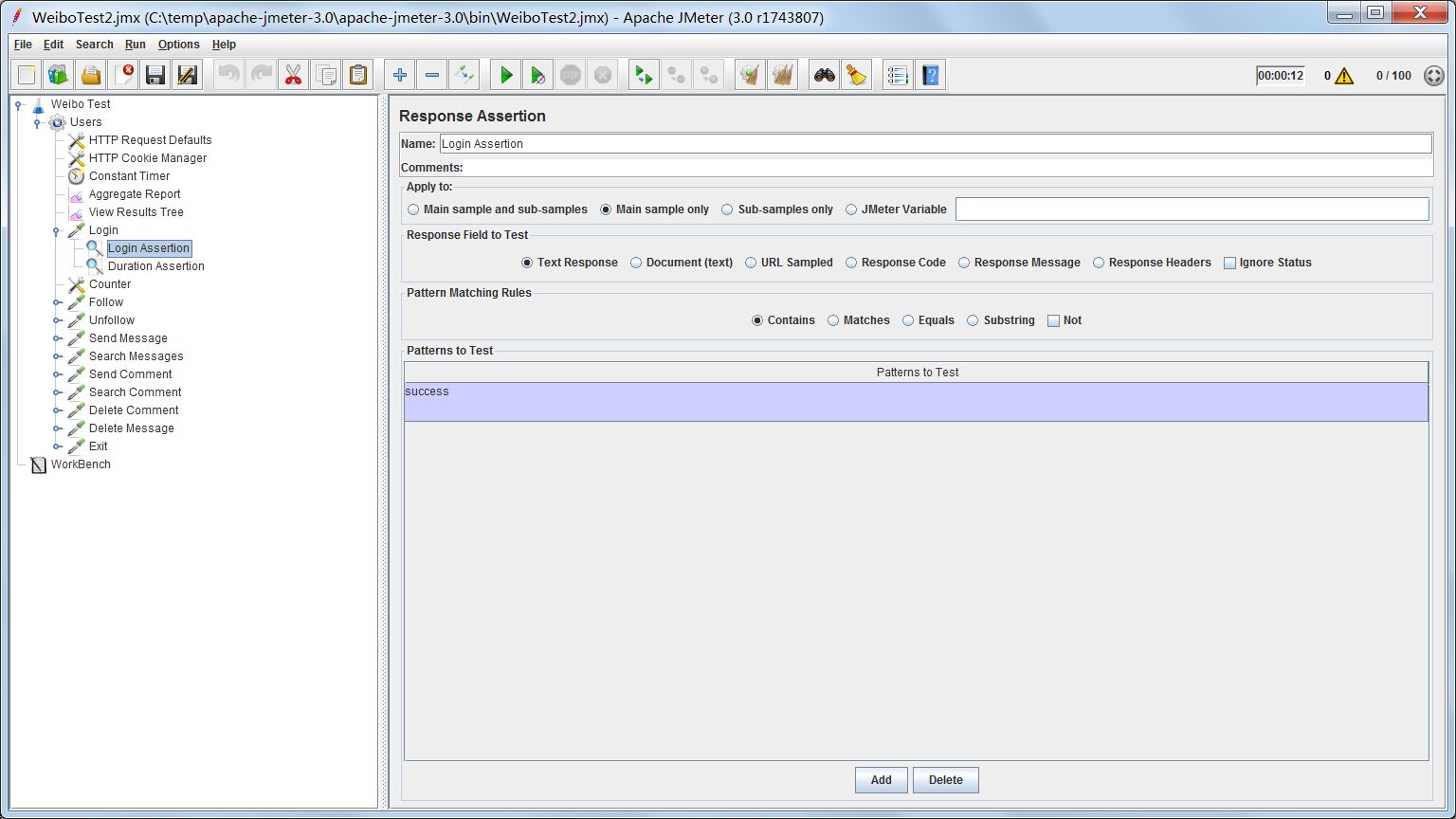
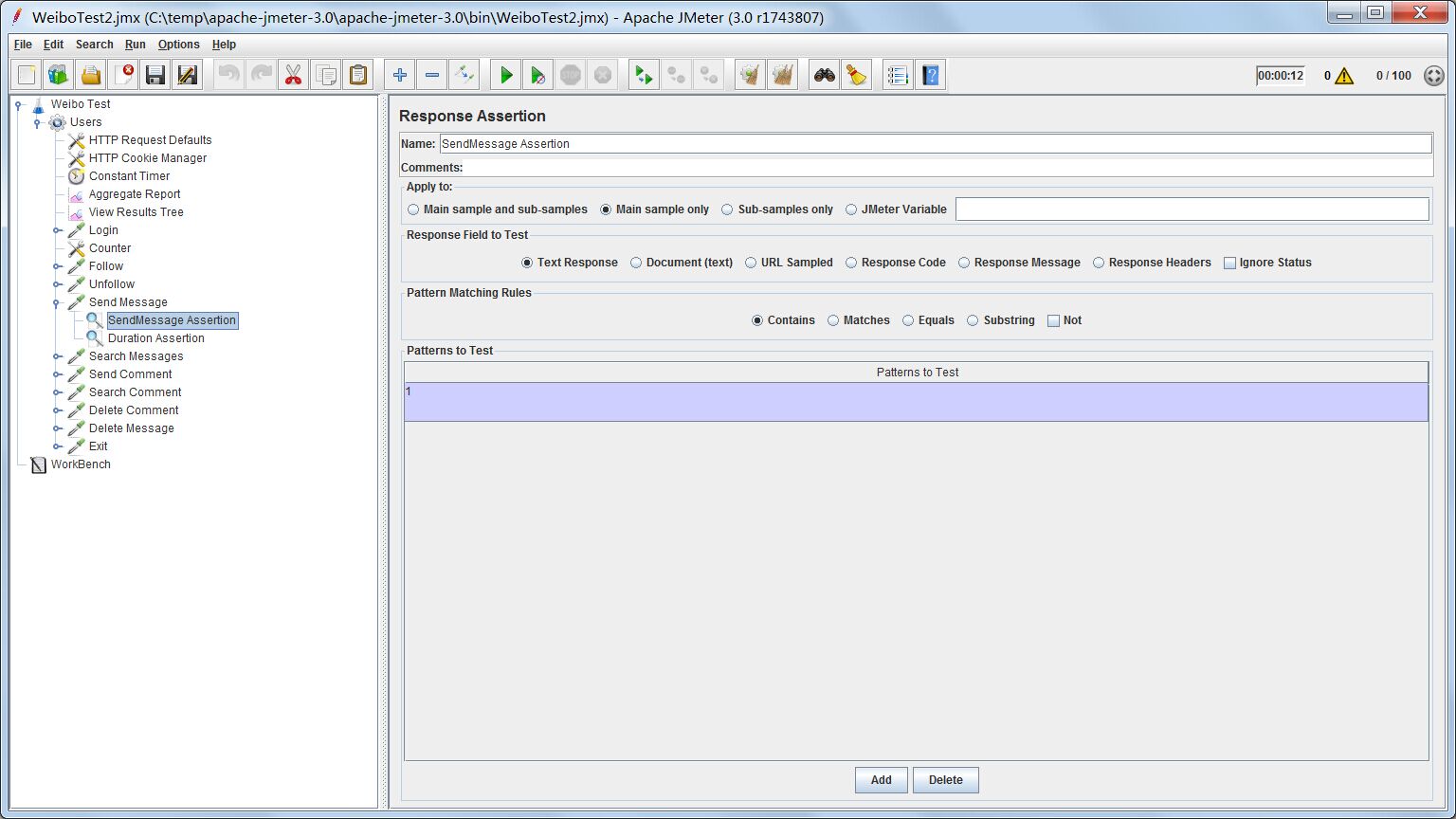
如果response返回含有”success”字段,就说明成功;否则失败。
下面进行的测试实例,全部使用Response Assertion。
Duration Assertion
只是返回结果正确,也不能达到测试效果。在实际业务环境中,页面返回的快慢是影响用户体验的致命因素。当并发量大时,用户在进行页面操作时很容易会有时延。因此,在进行压力测试时,我们有理由定义一个延时范围,当超过这个时间还没有response返回说明失败;在延时范围内返回response说明成功。Duration Assetion就是完成这项工作的。
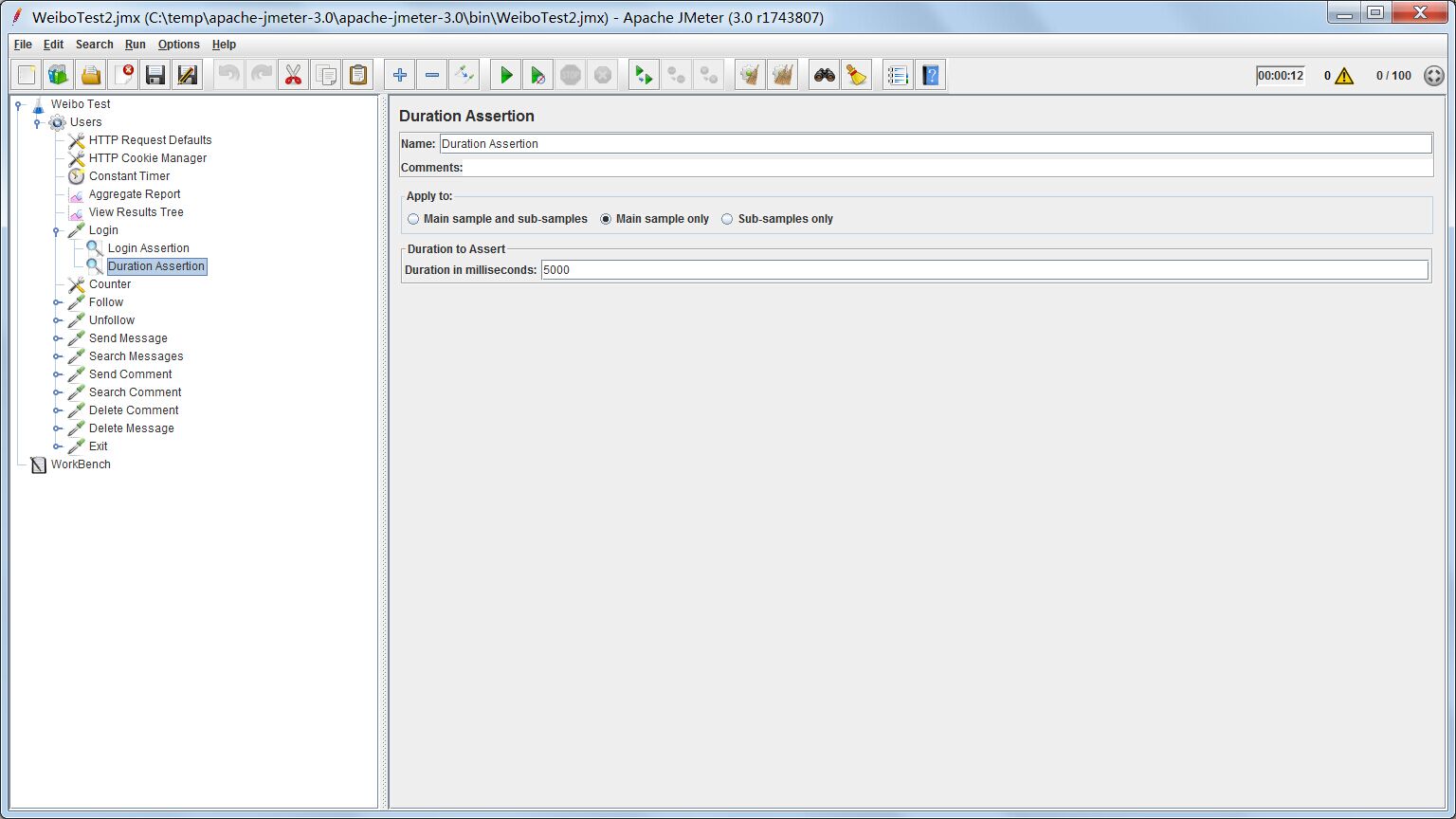
上面就定义了延时范围为5000毫秒。超过5000毫秒还没返回http response视为失败;否则为成功。
下面进行的测试实例,全部使用Duration Assertion,且Duration in milliseconds全部设为5000毫秒,就不一一列举了,在分析时候只列出Response Assertion设置。
登录测试
测试配置
JMeter里对HTTP Request的测试是用Sampler里的HTTP Request进行的。我们可以在里面添加HTTP Request的Parameter,以及URI。
登录一般需要用户名和密码。为了测试方便,我预先在微博系统对应的数据库里添加好一定量的用户,他们的用户名与id相同,密码统一为gdzq。id按加一自增长的策略产生。下面是登录测试的配置:
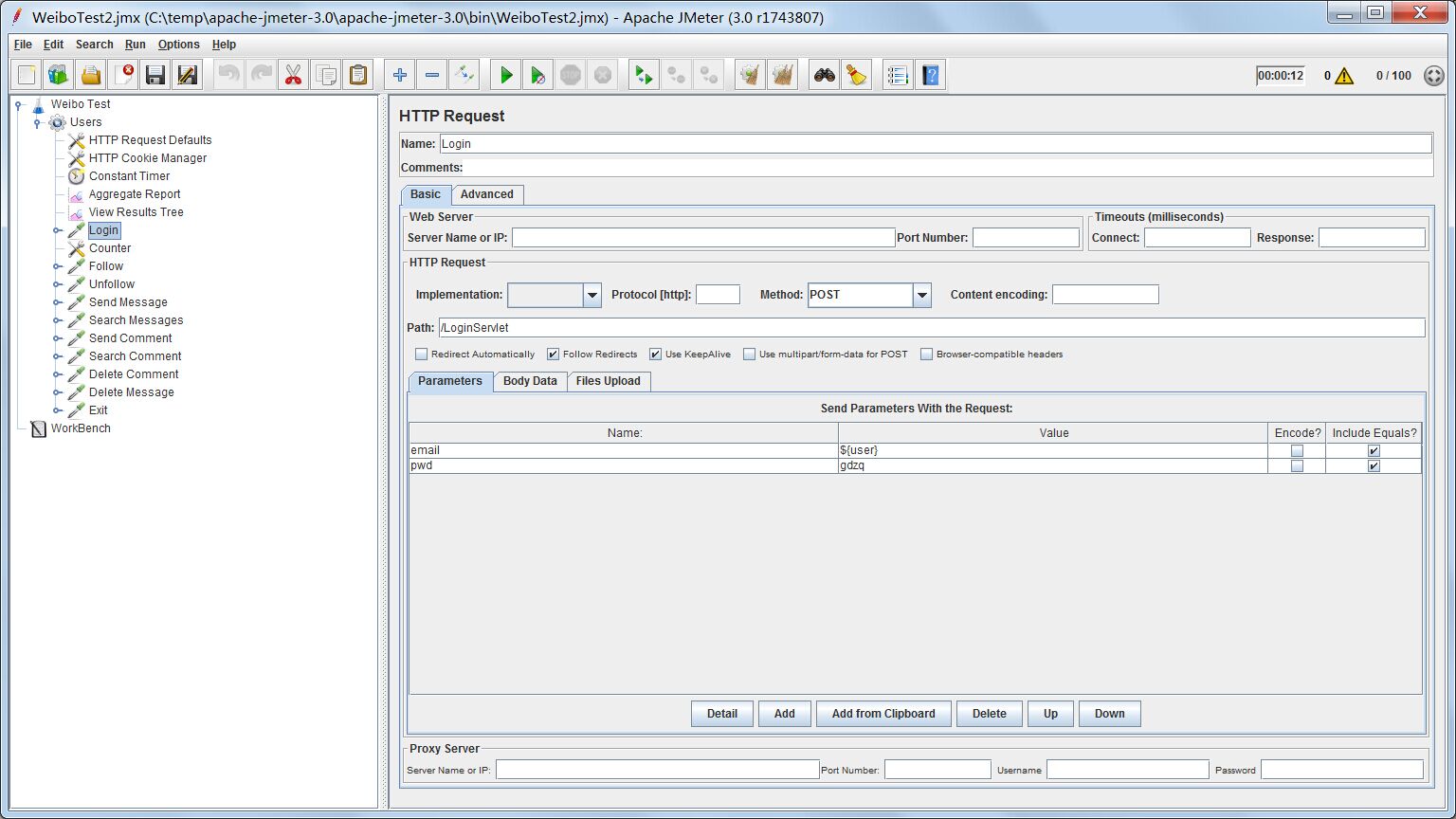
我们的登录功能是用LoginServlet这个serlvet实现的,它接收两个参数,一个是email,相当于用户名;一个是pwd,是密码。这些输入参数是有具体的Web系统确定的,我这个微博系统就是需要这两个。
由于要模拟多用户登录的场景,需要让每个线程的登录用户的不一样。按照上面的数据库里的测试用户的特点,在HTTP Request的参数里让密码固定为gdzq,用户名我们这里引入了一个变量User。
JMeter有很多途径产生变量,我们这里介绍一种很简单的,Counter。
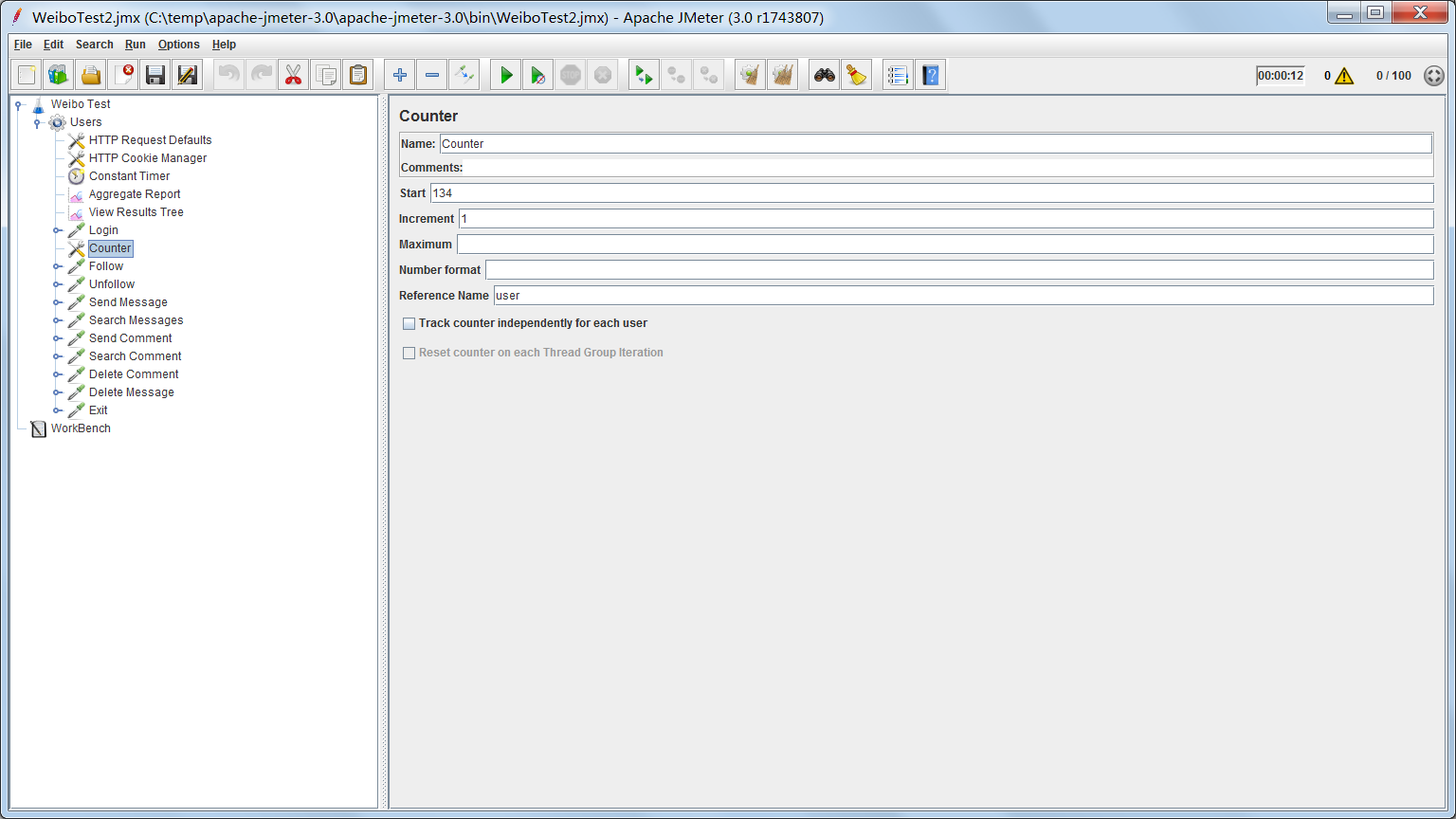
Start是变量的起始值,Increment是每次增加的值,Maximum是上限值,Reference Name是变量名。我们让User变量从134开始递增,每启动一个线程就会使用一次User变量,并把它增1,从而达到模拟不同用户访问系统的效果。
Response Assertion
关注某个人
测试配置
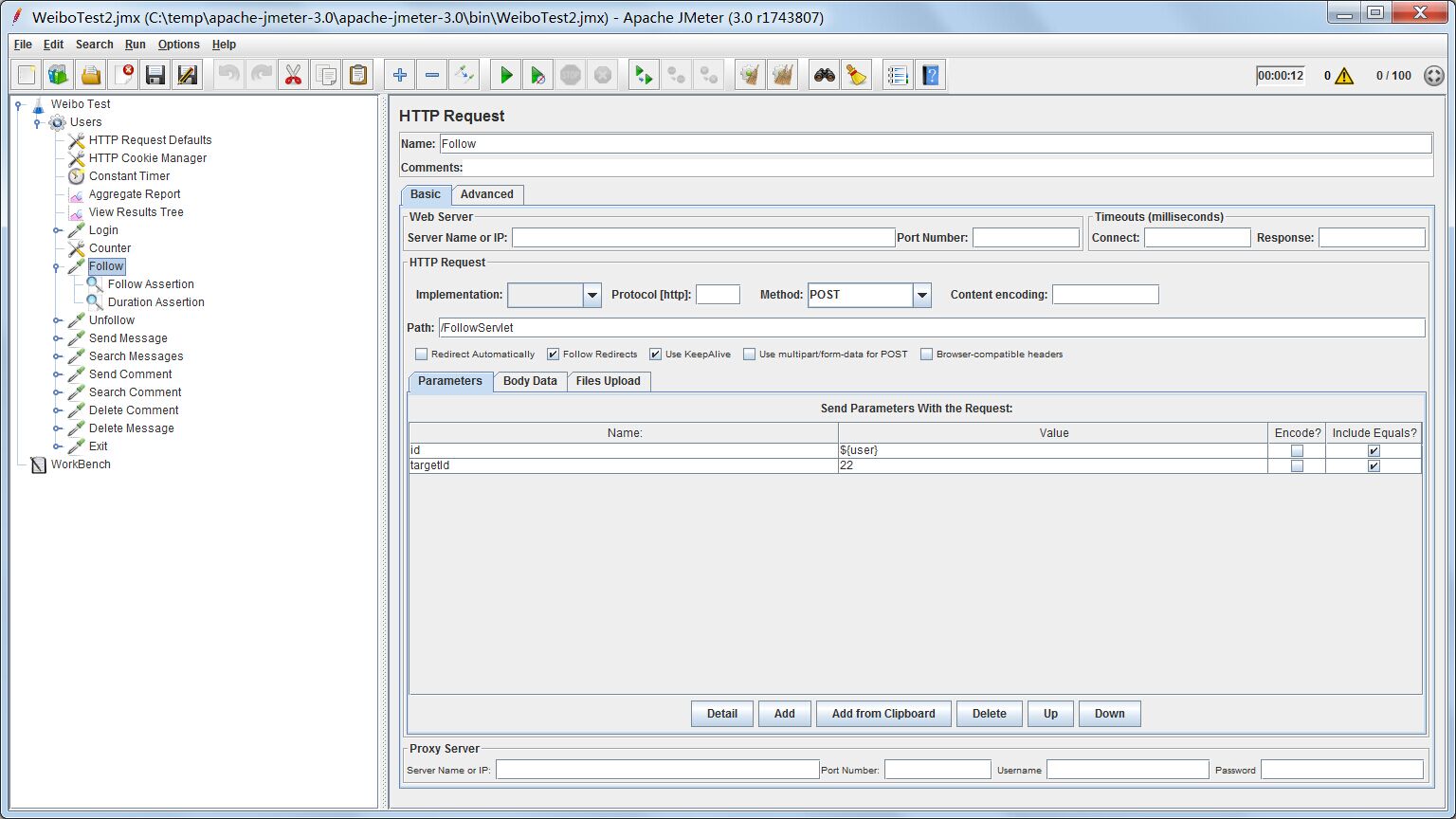
两个参数,一个是关注者id,一个是被关注者id。被关注者我们固定为22,关注者按照登录测试的逻辑,用User变量表示,模拟多用户并发关注同一个用户的情景。
Response Assertion
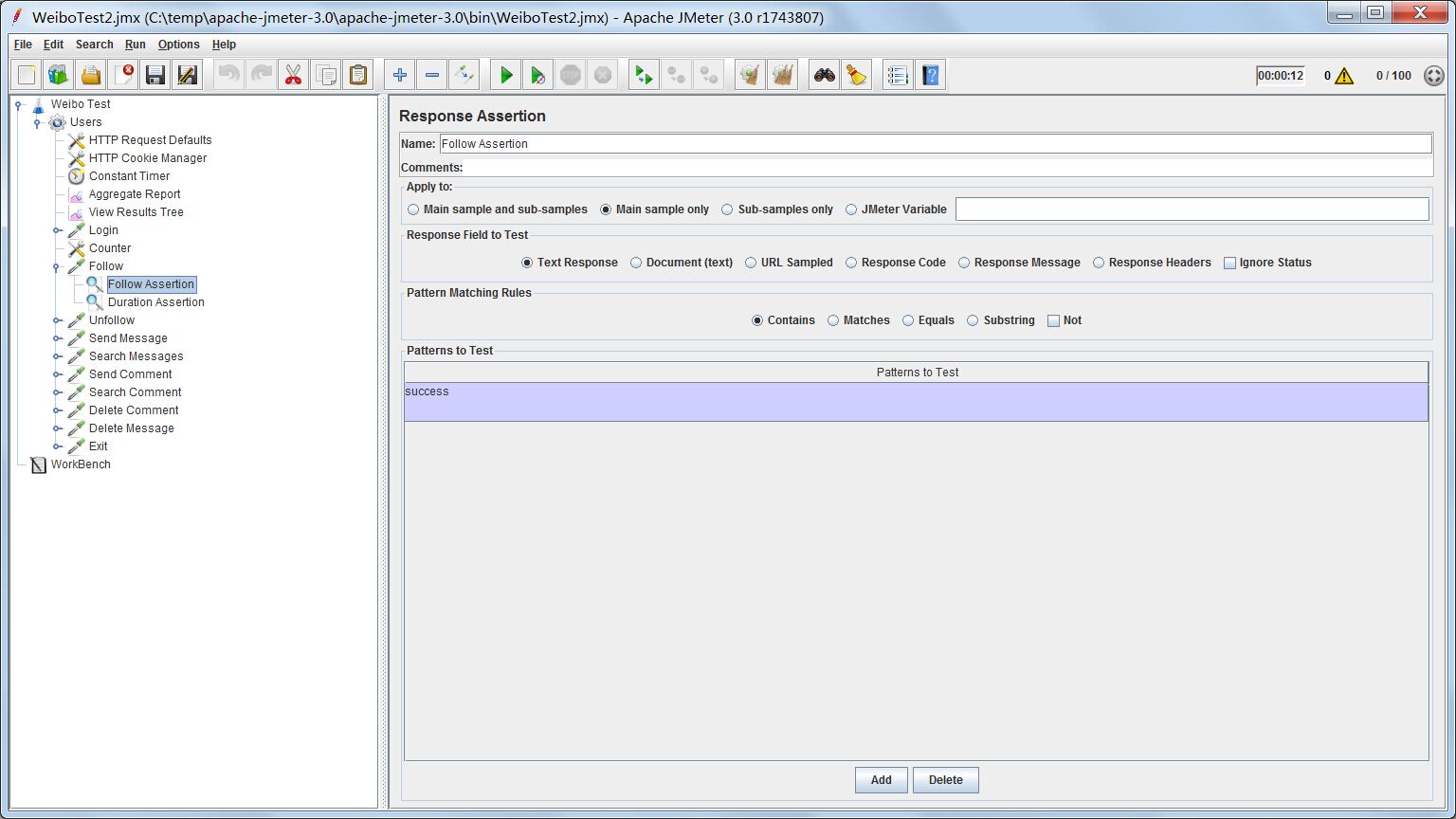
取消关注某个人
取消关注操作与关注操作的request参数和response返回都是一样的,就不另行分析了。
发送微博
测试配置
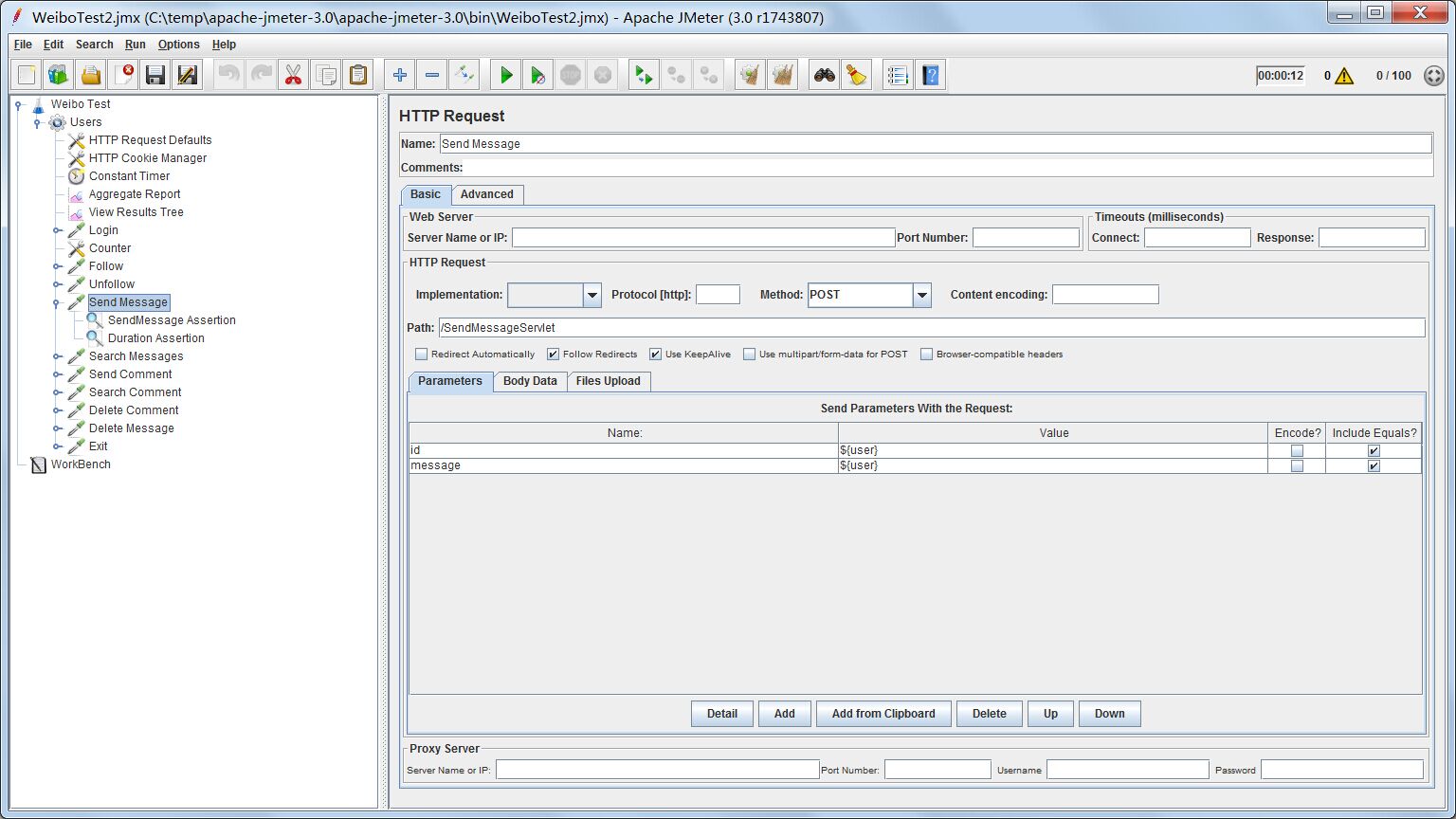
http request需要两个参数,id代表发送微博的用户的id,message代表微博内容。这里我们两个参数都使用User变量,每一个线程都代表不同的用户,不同的用户都发送一条微博,微博内容就是他们的用户id号。
Response Assertion
查找微博列表
测试配置
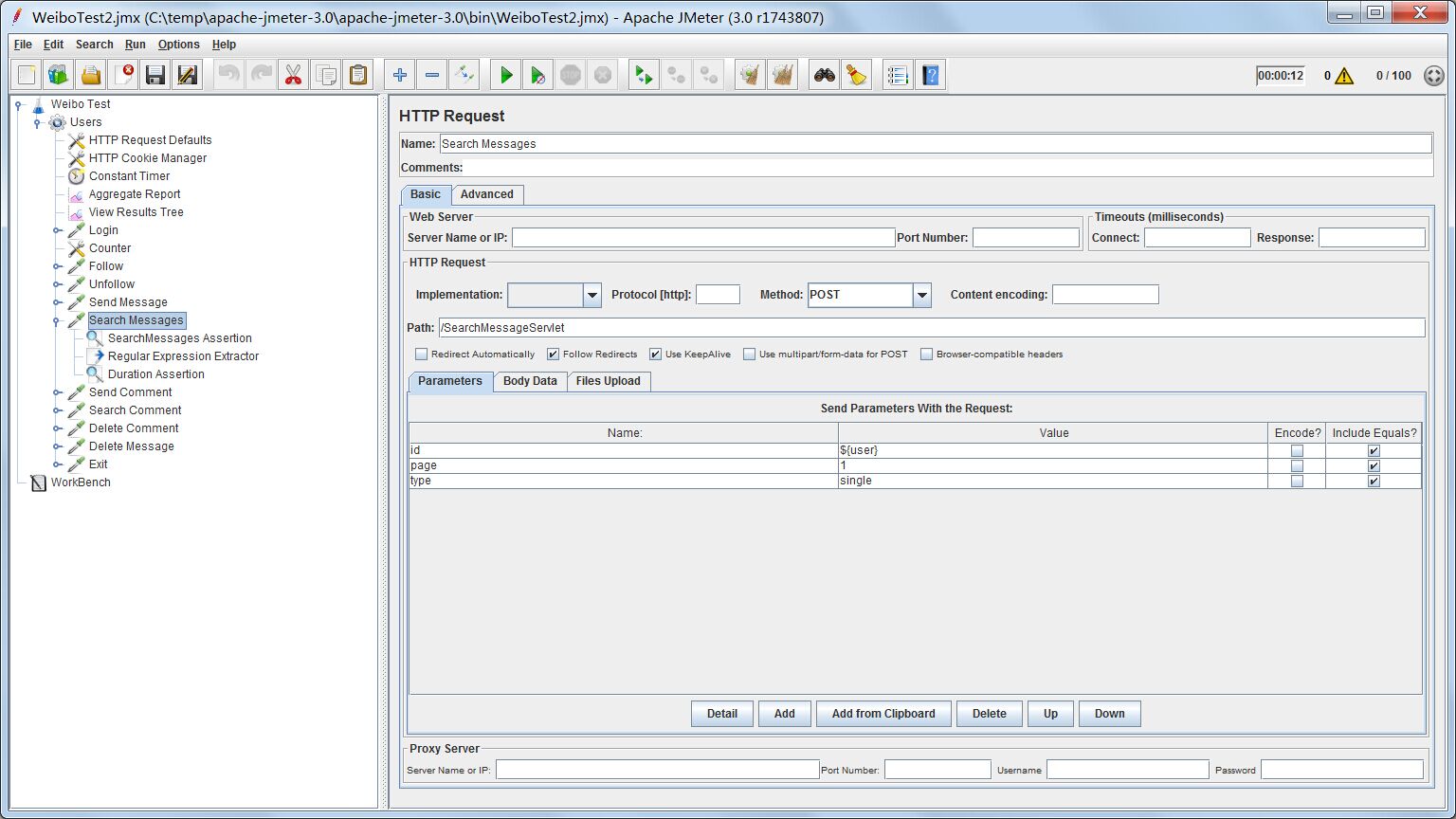
http request接收三个参数,id代表要查找哪个用户的微博列表,这里仍然使用User变量;因为微博可能很多,需要分页,page代表要查找的微博列表的页数,这里固定为第一页;type代表查找类型,我设计的这个微博系统允许三种类型的查找,分别是全部,个人和最热微博。全部就是查找用户自己发表的微博以及用户关注的人发表的所有微博;个人就只是用户自己发表的微博;最热微博则是查找全系统评论数最高的10条微博。这里type固定为”single”代表只查找用户自己发表的微博。由于我数据库用于测试的用户本身并没有微博数据,仅有的微博就是上一个操作发送的那条微博,因此查找结果应该只含一条微博。
Response Assertion
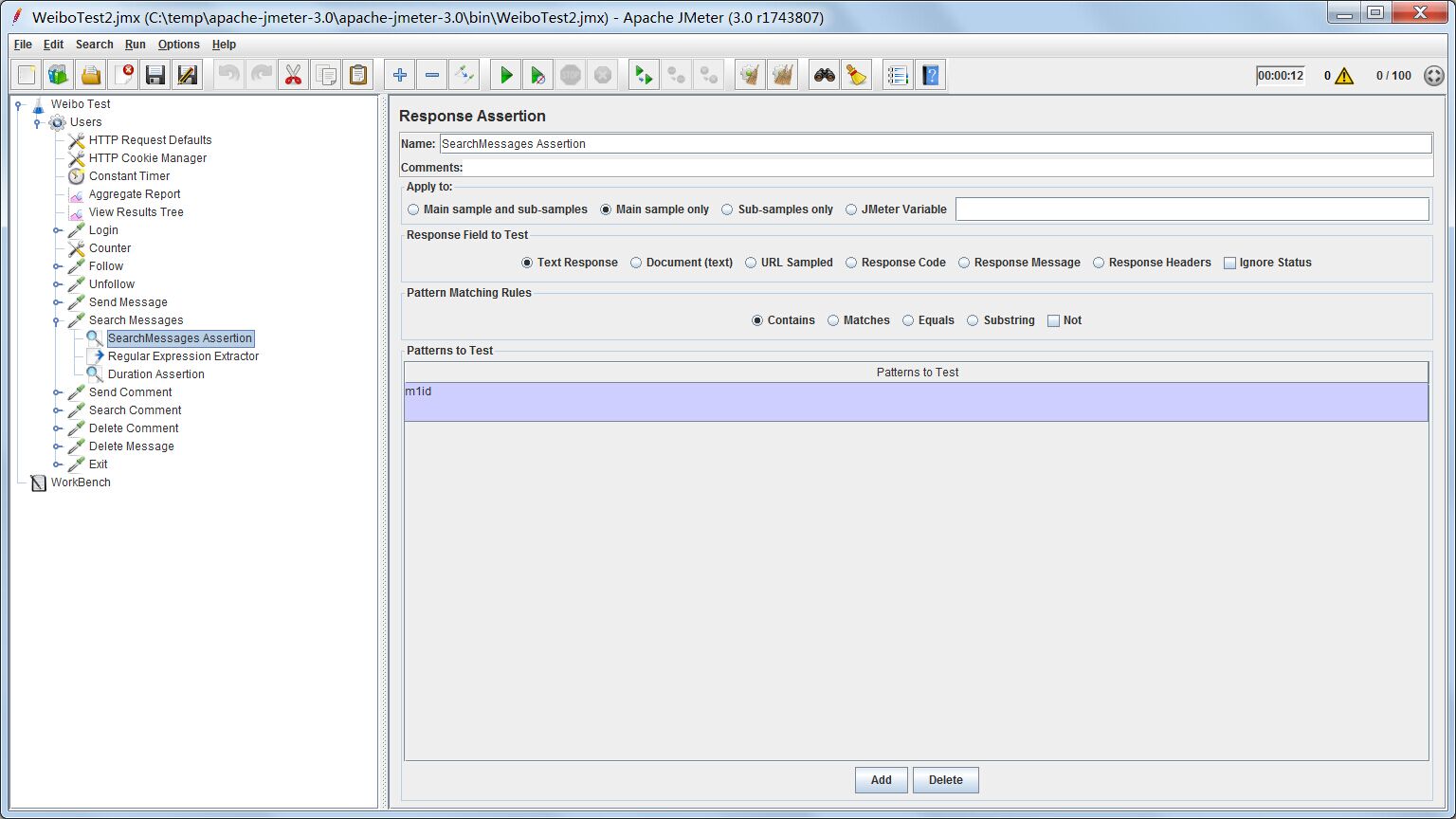
如果访问正确,应该返回m1id字段。我这个SearchMessageServlet的response返回的是微博列表,格式是json。json里包含着m1id字段,代表是查找出来的微博id。由于测试用户只有一条刚刚测试时发表的微博,所以只有一个m1id字段出现。
Post-Processors中的正则表达式提取器
Post-Processors是Sampler运行完后会触发的一项组件,一般用于提取Sampler返回的一些数据。类似的还有Pre-Processors,是Sampler运行之前会触发的一项组件。正则表达式提取器便是Post-Processors其中一种,用于按正则表达式的语法提取response里包含的一些数据。
由于我们的测试后续需要测试往微博添加评论,查找评论,删除评论以及删除微博这些功能,都需要刚刚测试时用户发表的微博的id作为http request的输入参数。因此我们在查找微博的Sampler上添加一个正则表达式提取器,提取查找出来的第一条微博的id。这条微博就是测试时发表的微博。
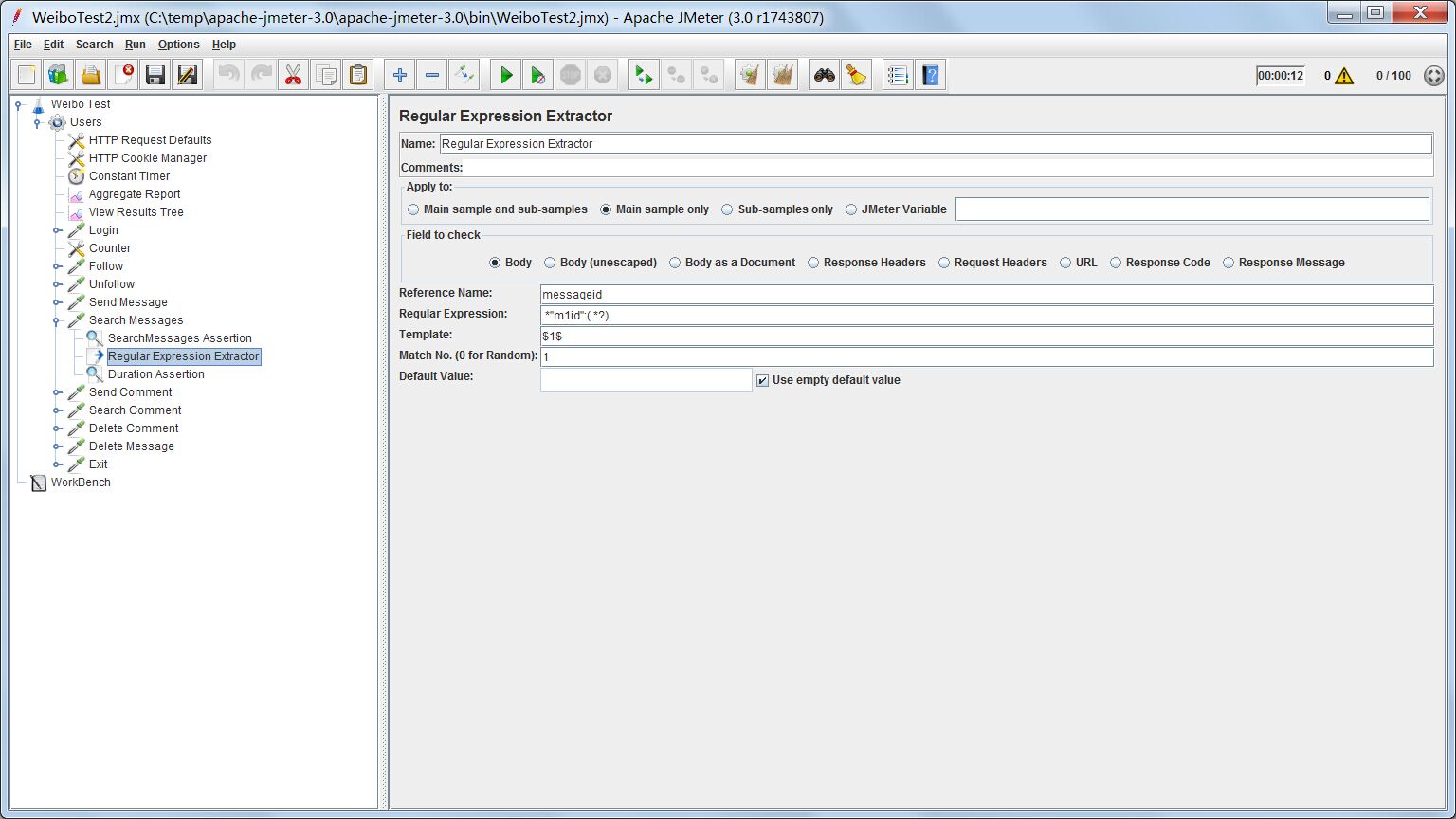
我们用正则表达式提取器产生引用名为messageid的变量,用于后续测试引用。因为我们的返回是json格式的数据,所以正则表达式为(.“m1id”:(.?),),提取json的key为m1id的数据。
Template代表我们希望提取第几个捕捉项,一般用括号括起来的作为一个捕捉项,上面的正则表达式只有一个。$1$代表提取第一个捕捉项。
Match No.代表我们希望提取第几个匹配组。由于我们在response里可能提取到一组满足正则表达式的匹配字符串,我们需要选一个或者几个出来作为我们的输出。0表示随机选择一个,-1表示选择全部。这里我们选1,代表提取第一个匹配到的匹配项。实际上,由于我们的测试用户只有一条微博数据,也只能匹配到一个。
发表评论
测试配置
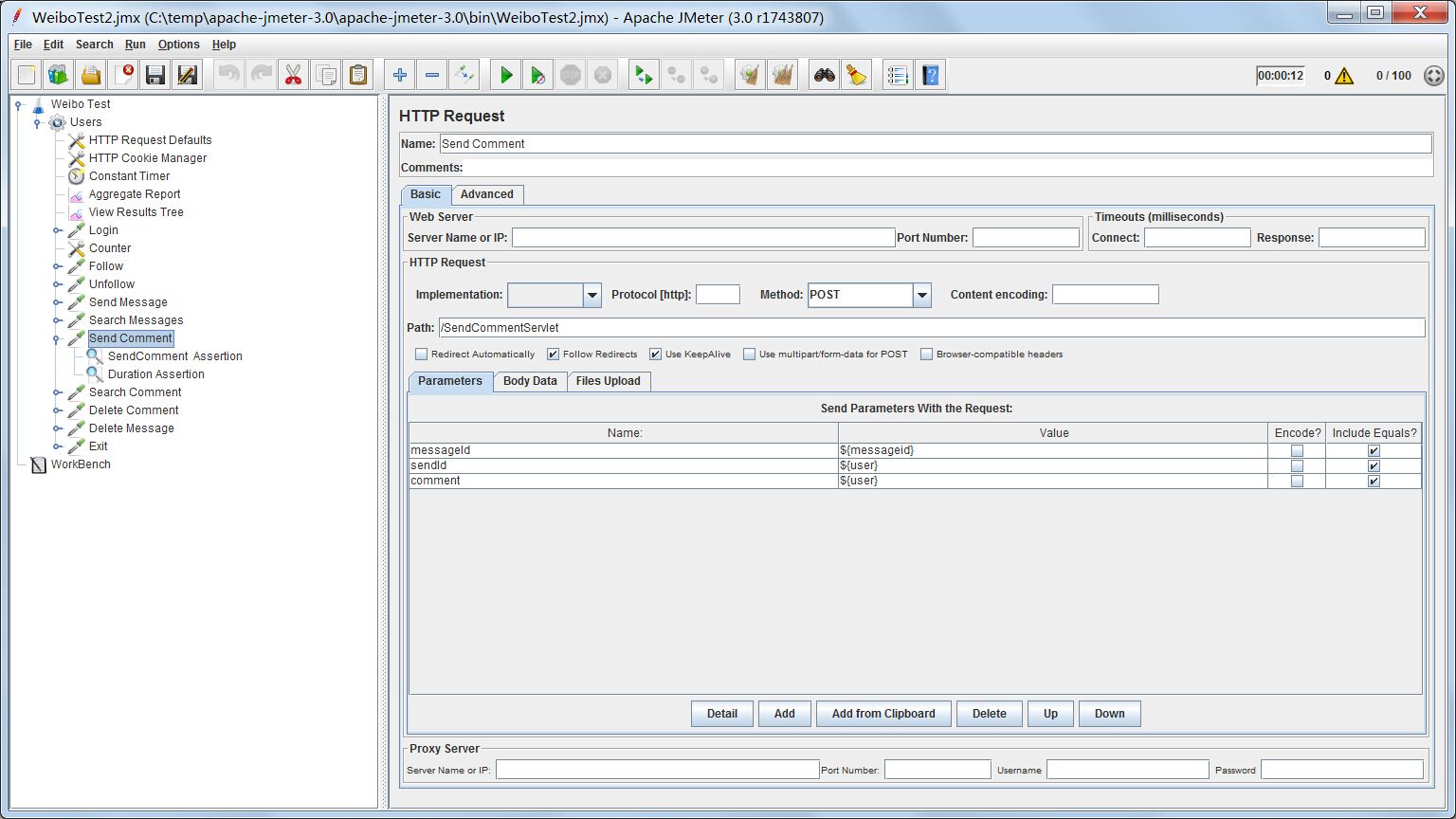
http request接收3个参数,messageId代表发表评论在哪个微博上,这里用之前正则表达式提取器提取的messageid变量作为值;sendId代表发表评论的用户id,这里仍然用User变量;comment代表评论的内容,这里为了方便,直接用User变量作为评论的内容。
Response Assertion
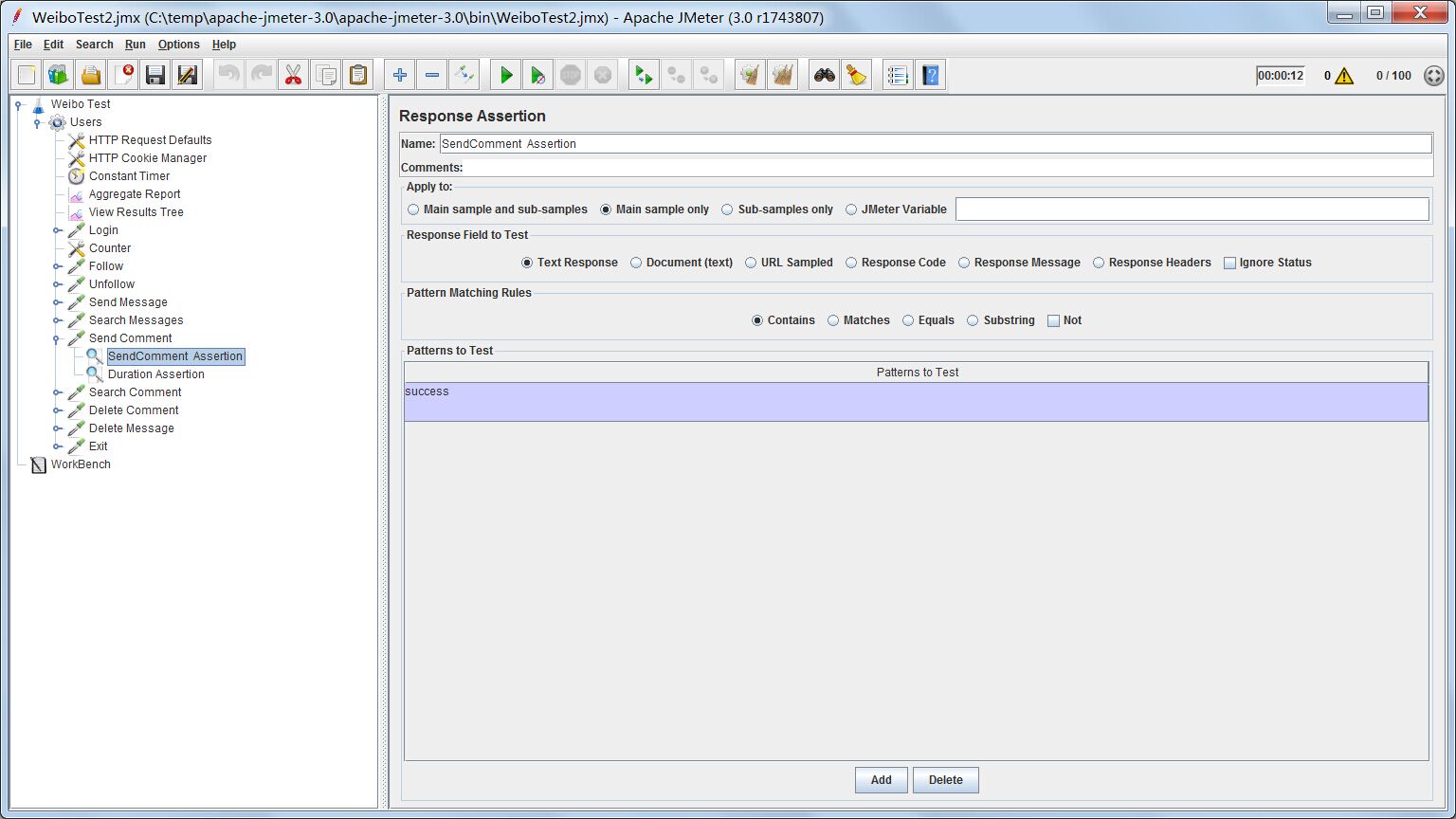
查找评论列表
测试配置
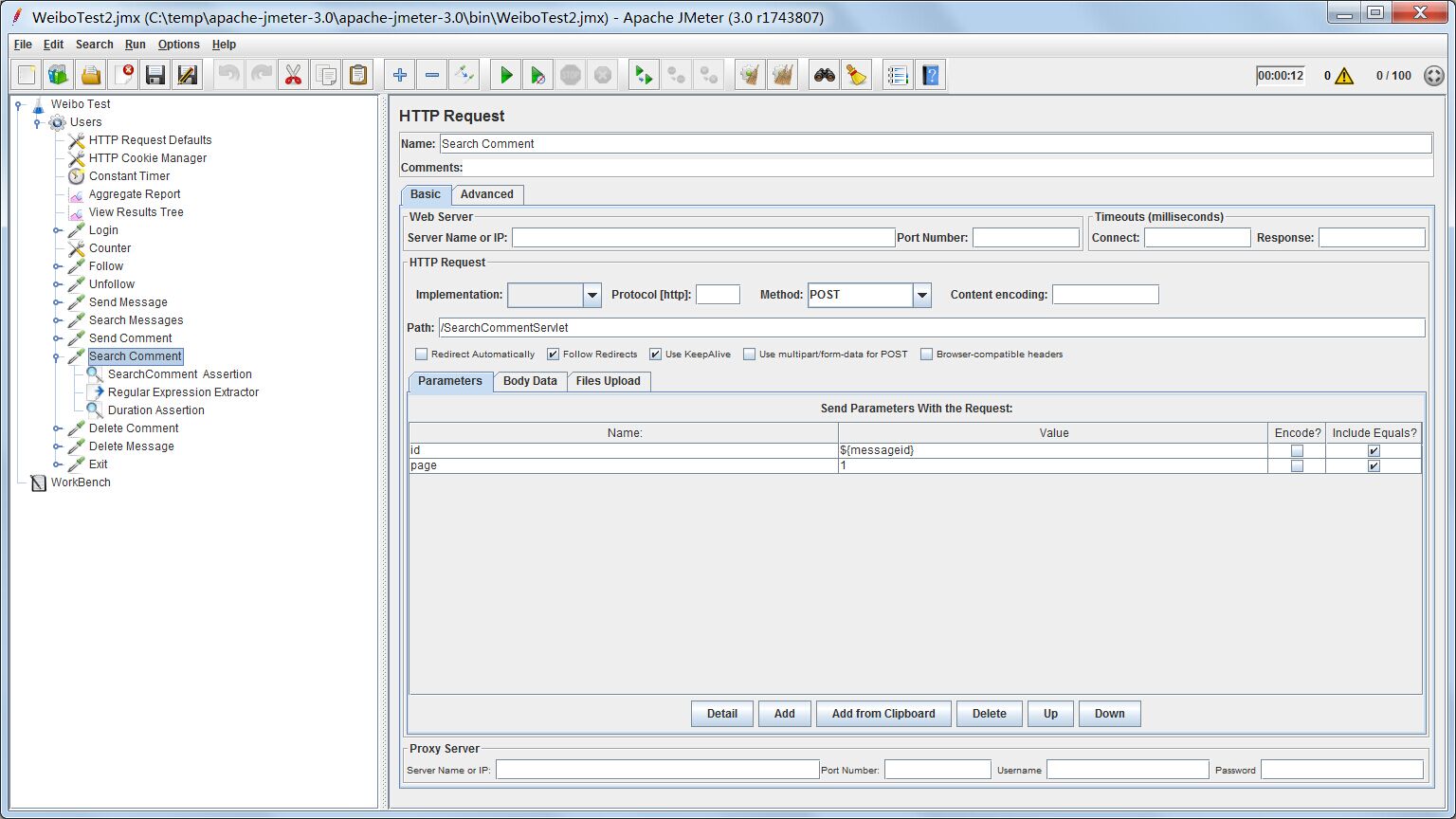
http request接收2个参数,id代表查找哪个微博的评论,这里仍然用messageid变量;page代表页码,因为评论列表也是需要翻页的,这里固定为第一页。
Response Assertion
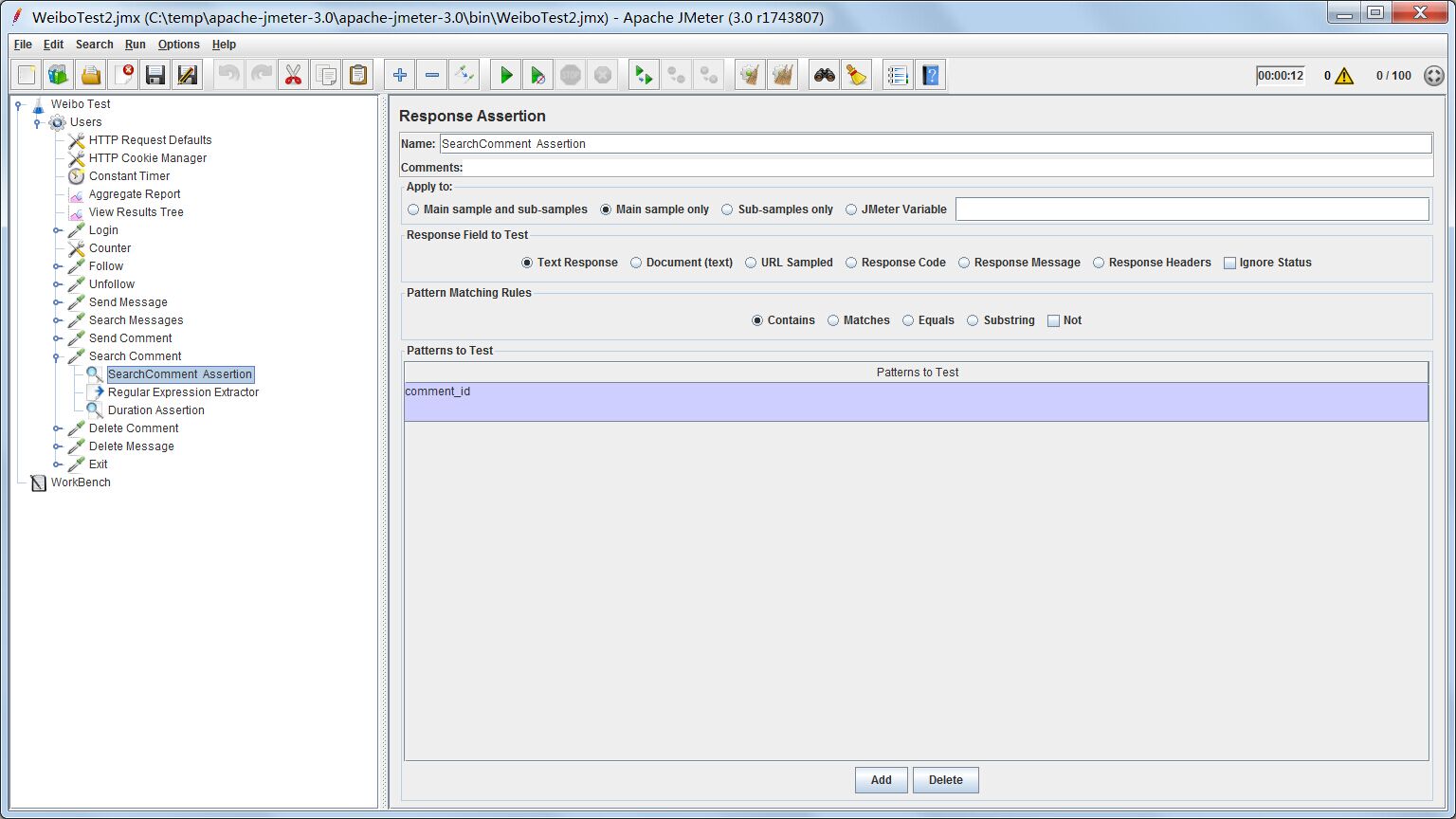
response会返回json格式的数据,comment_id是json里的key,代表对应的评论的id。通过判断response是否含有comment_id字段,可以判断测试是否正确。
正则表达式提取器
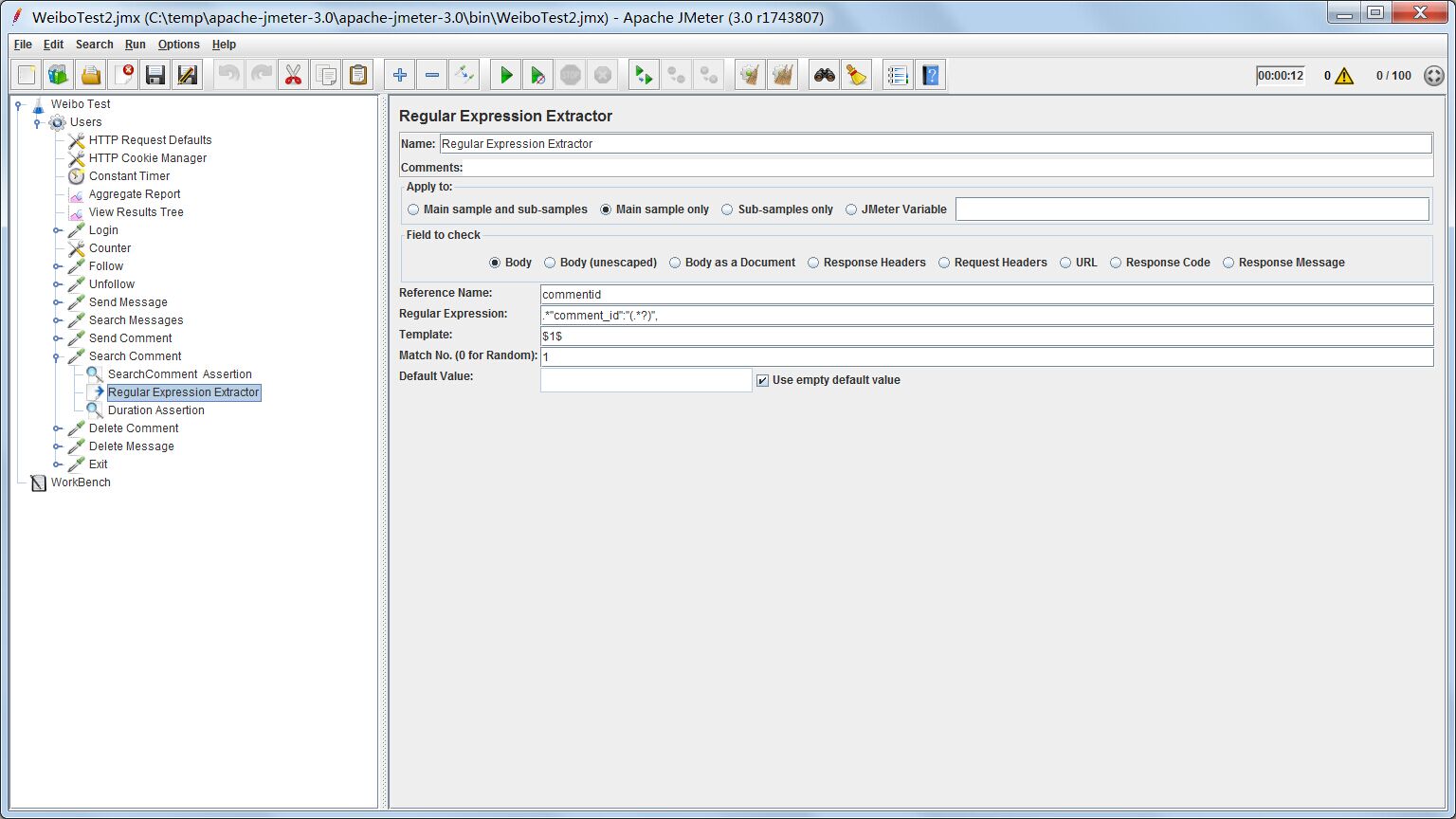
与查找微博列表一样,查找评论列表也需要设置一个正则表达式提取器,提取返回的评论列表的第一条评论的id。由于测试用户只有一条微博一条评论,这条评论id就是刚刚发表的评论的id。这个id继续作为下面删除评论测试的输入参数。
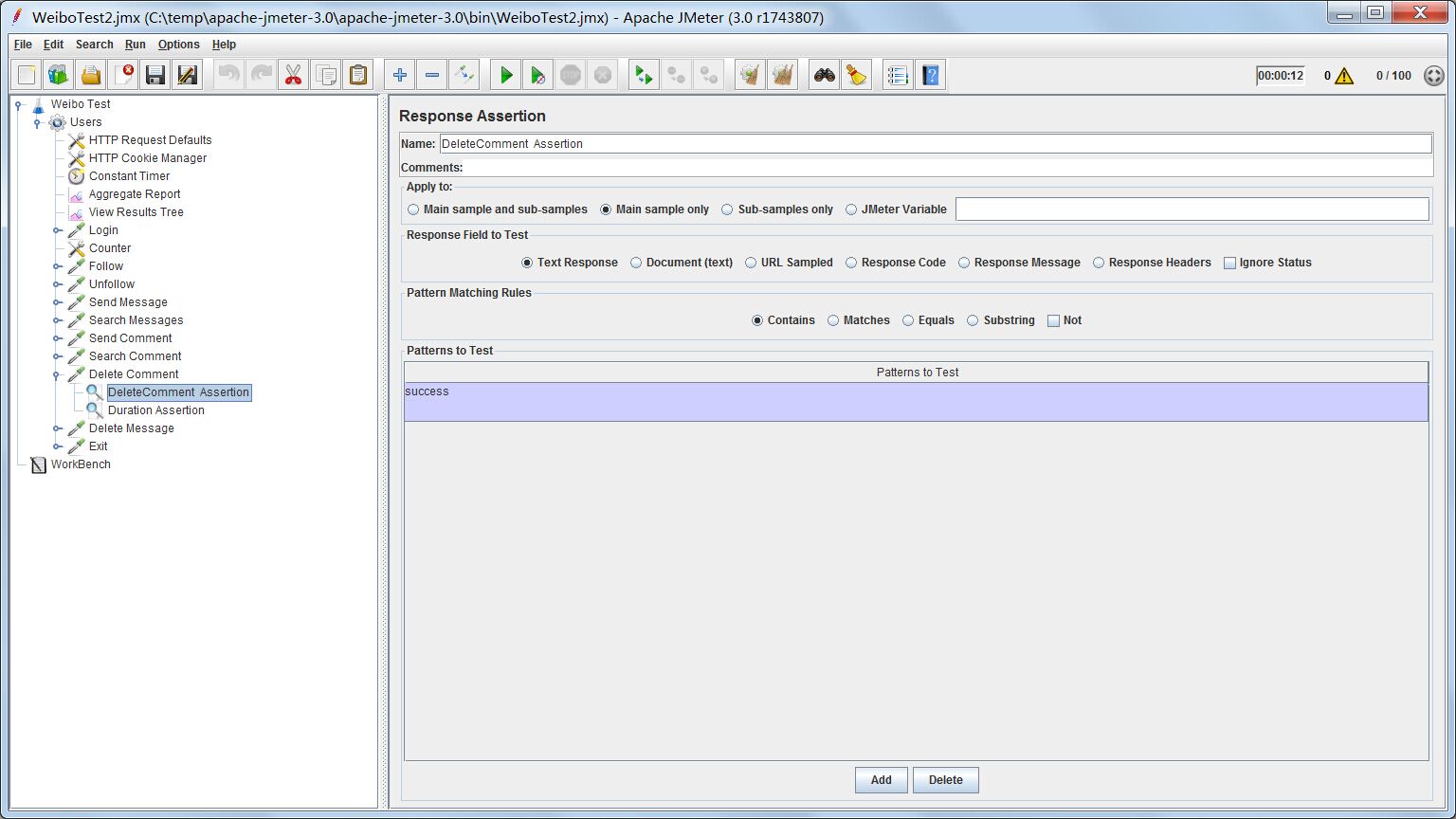
删除评论
测试配置
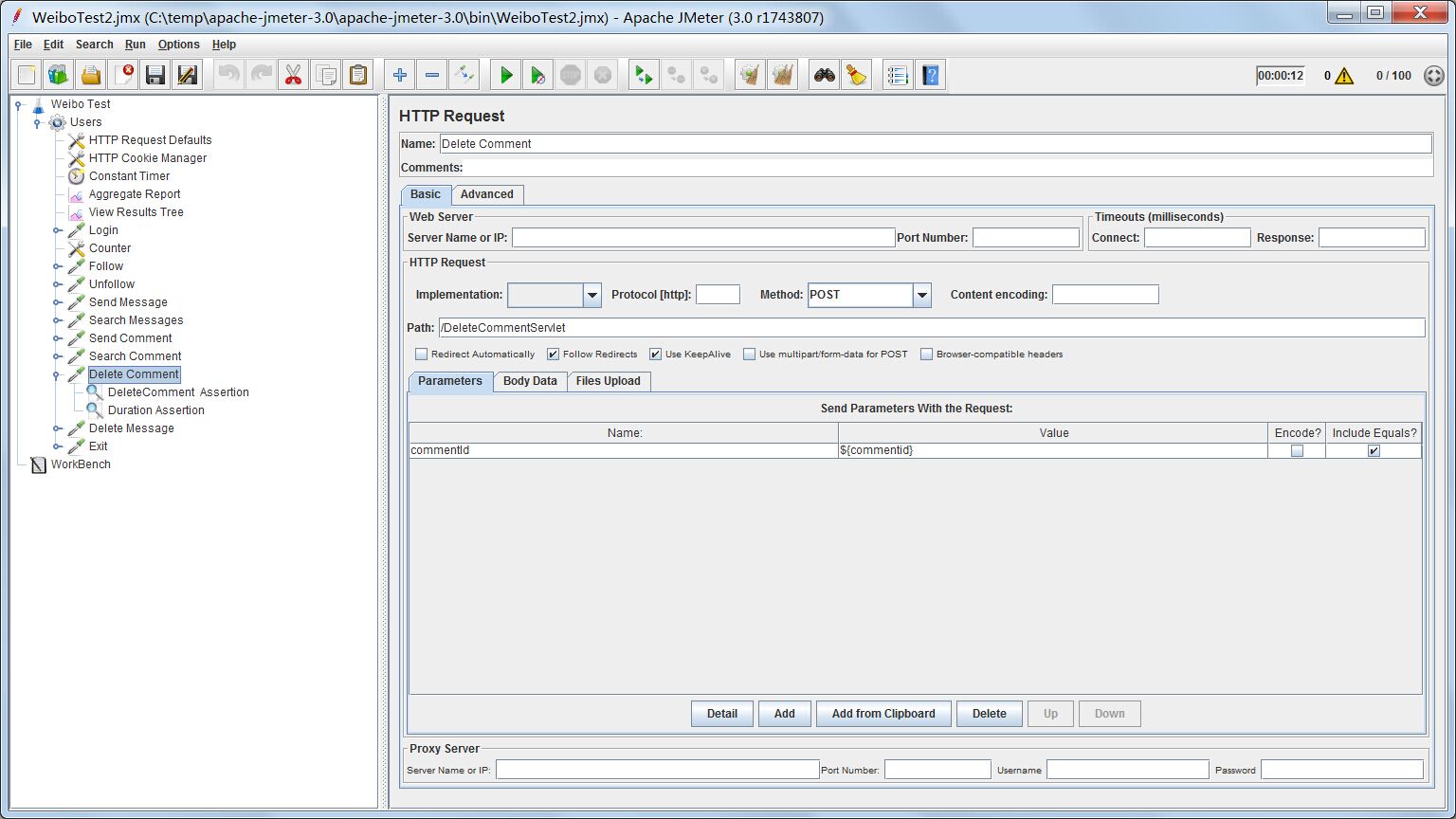
http request接收1个参数,commentId就是上面正则表达式提取器产生的变量,代表评论id。只要把评论id作为DeleteCommentServlet的参数,就能实现删除评论的功能。
Response Assertion
删除微博
测试配置
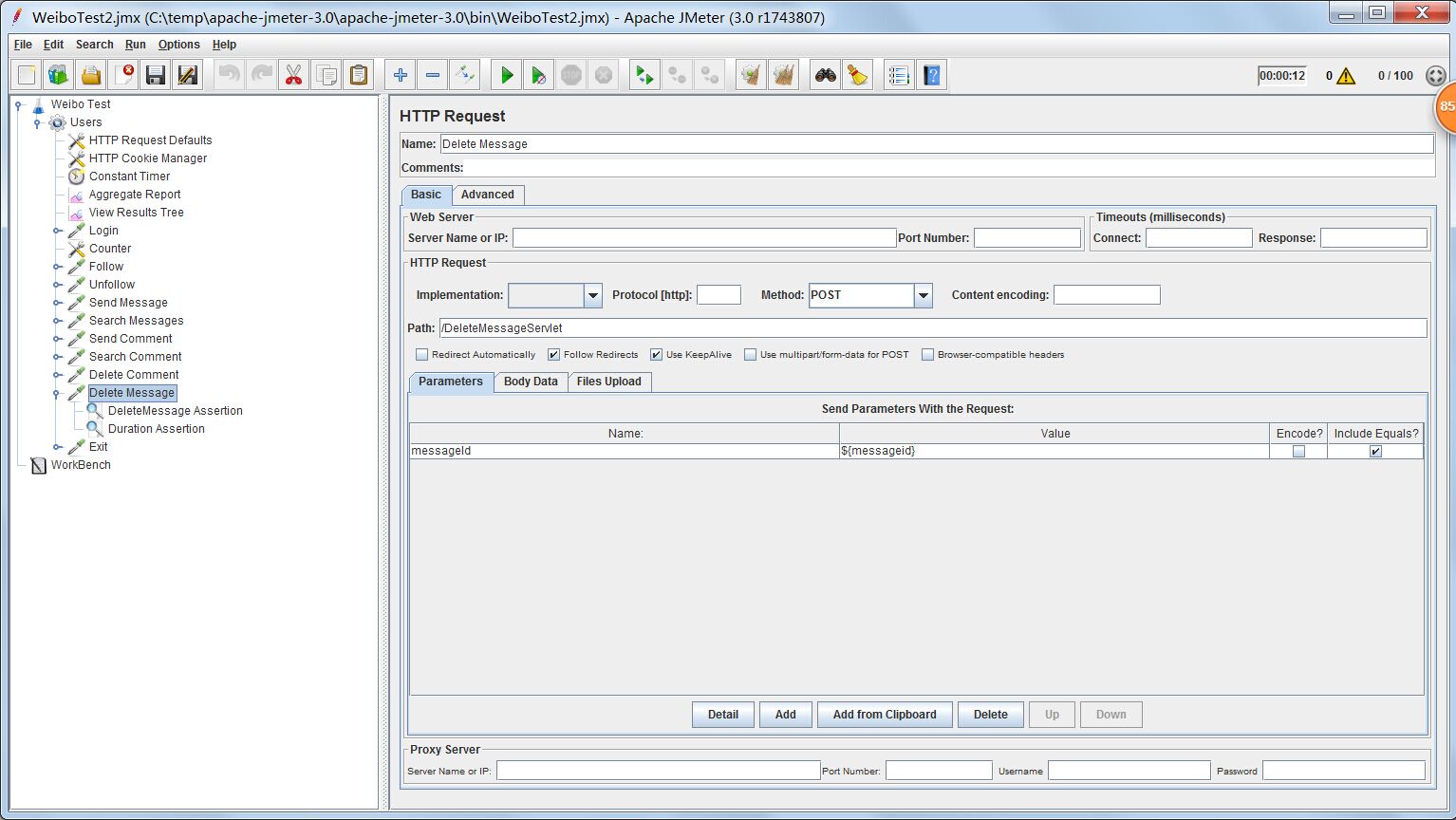
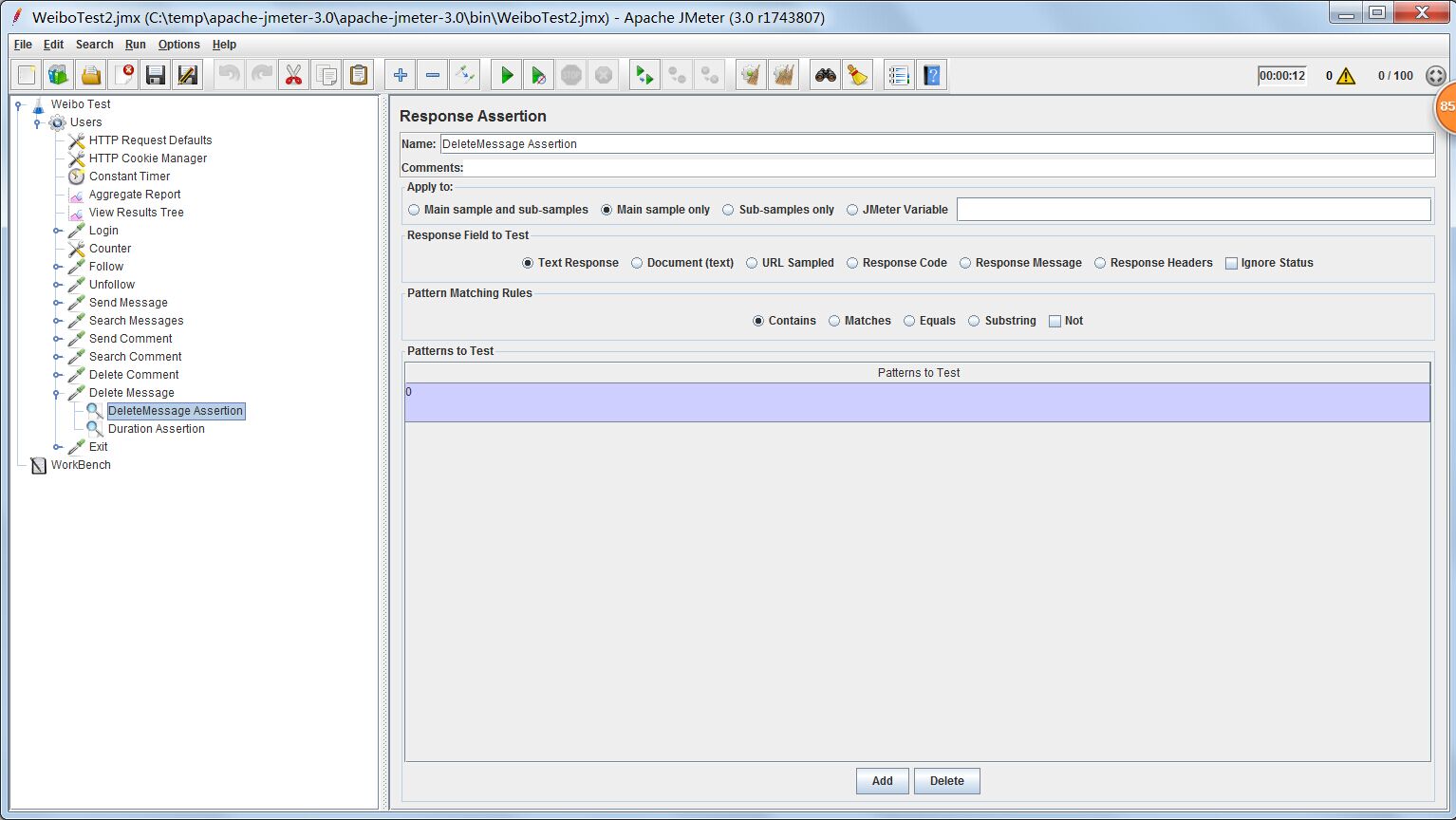
http request接收1个参数,messageId就是上面正则表达式提取器产生的变量,代表微博id。只要把微博id作为DeleteMessageServlet的参数,就能实现删除微博的功能。
Response Assertion
登出测试
测试配置
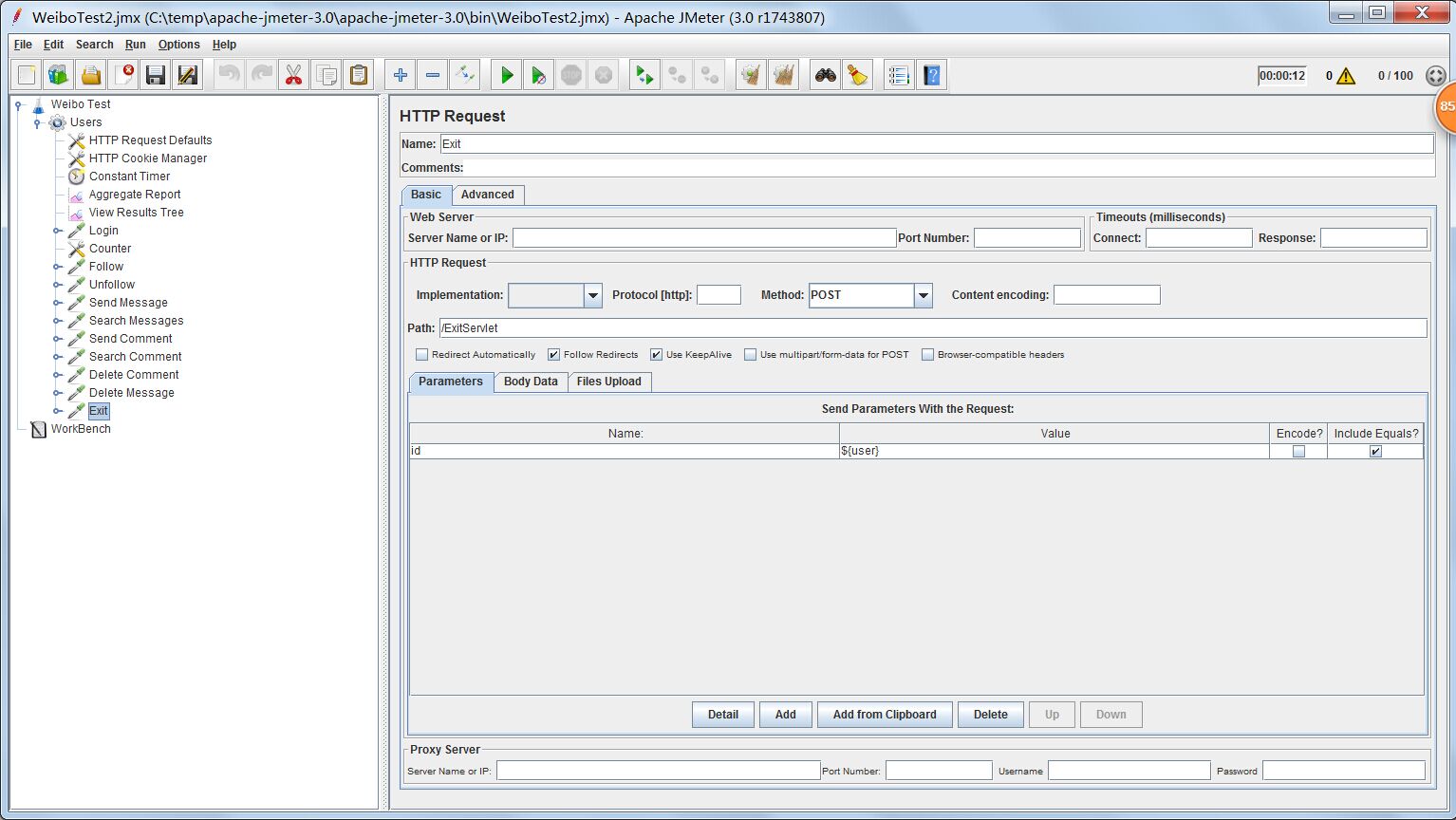
http request接收一个参数,id代表要登出的用户id,这里用User变量。
Response Assertion
总结
上面的实例通过具体的微博系统的测试,引出了一些JMeter的一些最基本最常用的组件。学会使用这些组件,就能搭建一个基本的测试系统,完成基本的压力测试任务。上面的具体测试细节可以不用关注,但要关注从这些实例引申出来的Sampler,HTTP Request Defaults,HTTP Cookie Manager,Assertion,测试报告,断言,变量,正则表达式提取器以及Post-Processors和Pre-Processors等概念。
在完成了上述配置以后,只要不断地试验、修改启动的线程数,启动时间等参数,便可以得出Web系统在并发访问下的性能临界点,由此作出可行的优化。