从丢失更新说起
上一讲提到了数据并发在数据库中的四大问题,其中一个便是丢失更新。丢失更新的产生是当两个事务同时读某一记录时,A事务先修改该记录,B事务再修改的时候把A的修改覆盖掉,导致A事务的更新丢失了。更具体的例子可以参考上一讲。数据库处理丢失更新有两种方法,分别是悲观锁方法与乐观锁方法。
悲观锁与乐观锁
对于某一特定的业务需求,如果实现该需求需要并发地更新数据库的同一记录,就有可能发生冲突。解决这种冲突可以选择两种办法,分别是悲观锁与乐观锁。
- 悲观锁:悲观锁认为更新冲突是经常发生的,因此通过传统加锁的办法,让事务分别独占某一记录,解决并发的冲突。具体到丢失更新这一问题,悲观锁的解决方法有两个,第一是用select for update,手动加上排它锁,在整个事务周期内便不可能再允许其他事务修改或读取这一记录;第二是用Repeatable Read的事务隔离级别,让共享锁与排它锁的持有时间都是整个事务周期,便自然杜绝了并发更新的发生。
- 乐观锁:乐观锁认为更新冲突是几乎不会发生的,当发生冲突时便会阻碍,返回错误信息,让用户决定重新开启事务还是放弃。乐观锁的实现一般是应用程序级别的,数据库里很少提供这种实现。具体的方法是在所有元组后面都加上版本号属性,每次修改记录都会更新版本号。用户在读取记录的时候把版本号一同读出,在修改时候再判断版本号是否与原来的一致,一致则继续更新,否则说明有其他事务更新了该记录,返回错误。
什么是MVCC
MVCC,即多版本并发控制,是一种与传统锁机制有区别的一种控制并发的方法。从上一讲看到,事务隔离等级从低到高就是锁的不断增多的过程,必然导致性能的逐渐下降。而MVCC,则做到了读与读不冲突,读与写不冲突,只有写与写才需要锁去控制冲突。不同的读操作根据事务版本的不同,看到的视图是不一样的。因此即使事务A修改某一记录,事务B读到的记录是处于另一版本视图下的,与事务A的写操作自然隔离了,并不需要锁的控制。这种多版本控制读操作视图的方法,在PostgreSQL里实际上是采用了乐观锁来实现的。下面我将先阐述PostgreSQL里MVCC是如何与事务隔离等级结合起来的,然后再仔细分析MVCC的实现原理,由表到里地分析PostgreSQL里的MVCC机制。
PostgreSQL MVCC与事务隔离等级
上一讲我们讲到了数据库的事务隔离等级要求,但这只是最低的要求,实际上具体数据库的实现可以更加严格,每个数据库的实现机制与锁控制方式也大相径庭。下面我们先来看看PostgreSQL的事务隔离等级是怎么样的:
| Isolation Level | Dirty Read | Nonrepeatable Read | Phantom Read | Serialization Anomaly |
|---|---|---|---|---|
| Read uncommitted | Allowed, but not in PG | Possible | Possible | Possible |
| Read committed | Not possible | Possible | Possible | Possible |
| Repeatable read | Not possible | Not possible | Allowed, but not in PG | Possible |
| Serializable | Not possible | Not possible | Not possible | Not possible |
从上表可以看到,PostgreSQL的事务隔离等级更加严格。它实际上只有3个隔离等级。如果选择了Read uncommited,相当于选择了Read commited,因为Read uncommited也是不允许脏读的。而Repeatable read级别在postgreSQL里也不存在幻读。除此以外,这里还引入了一个新的数据冲突问题:序列化异常。Serializable与Repeatable read在postgreSQL里是基本一样的,除了Serializable不允许序列化异常。关于不同事物隔离等级的具体细节,下面将一一介绍。
Read commited
主要看看Read commited是怎么解决脏读的。当事务处于这一隔离等级时,每次读写操作前都会对目前数据库拍一个快照,这个快照就是在当前读写操作发生前,所有已提交的事务对数据库做出的所有更改的结果。因此,在读操作进行时其他事务发生的更改都不会影响这个快照。而由于这个快照包含的是所有已提交的更改结果,因此其他未提交的事务作出的所有更改都不会被当前读操作看到,从而避免了脏读的发生。这就让读与写彻底分离开来,因为读写操作看到的数据库是不一样的。要注意的是,当前事务对数据库作出的修改会影响快照,可以被当前事务的读操作读到修改后的元组。
那么写与写冲突怎么办呢?
实际上,对某一记录的写操作在postgreSQL里仍然是加锁的,只是这个锁只阻塞写,不阻塞读。当事务A更改了某记录而未提交,事务B又要更改该记录时,事务B便会阻塞,直到事务A提交或回滚。如果事务A回滚,说明该记录的更新没有生效,则事务B继续正常更新该记录;如果事务A正常提交,事务B便需要判断原更新条件是否仍然生效,如果仍生效则继续B的更新,否则直接忽略B的更新。
然而对于某些较为复杂的查询,Read commited的级别是会产生一些问题的。下面我就分析一下官方文档给出的错误例子:
|
|
假设现在数据库有一个website表,该表有一个hit属性。目前数据库里该表只有两条记录,分别是hit=9与hit=10。现在又有两个事务,事务A进行update操作,事务B进行delete操作,如上面代码所示。update操作前会对数据库拍一个快照,此时快照里分别是hit=9和hit=10的两条记录,我们记为记录x与记录y,操作后记录x的hit=10,记录y的hit=11。delete操作前也会对数据库拍一个快照,因为快照仅包含已提交的事务产生的结果,因此此时快照里只有记录y(此时记录x的hit=9,记录y的hit=10)。由于存在并发更新,因此事务B的delete会阻塞。当事务A提交后,记录y的hit=11,已经不满足事务B的delete的条件,因此事务B的delete操作失败。而实际上,我们更希望事务B能把记录x(由于事务A的更新此时记录x的hit为10)删除,但由于事务B的快照里不包含记录x,因此会被忽略。
Repeatable read
postgreSQL的Repeatable read解决了重复读与幻读的问题。当事务处于这一隔离等级下时,每次事务开启后进行的第一个读写操作前拍摄快照,此后在整个事务周期沿用这个快照,而不是在每一条读写操作前拍摄快照。因此,当事务A开启后,即便事务B对事务A读取的记录作出更改并提交,也不会影响事务A的快照。事务A由始至终读取的结果都是一样的。这个过程完全不需要锁的控制,两个事务都是并发进行的,并且互不影响,因为两个事务都是对自己拍摄的数据库快照操作。与Read commited一样,当前事务作出的修改会影响快照。
写与写的冲突仍和Read commited一样,通过加锁阻塞控制的。Repeatable read对于并发更新冲突更加严格,仍以事务A与事务B为例,当事务A更改了某记录而未提交,事务B又要更改该记录时,事务B便会阻塞,直到事务A提交或回滚。如果事务A回滚,说明该记录的更新没有生效,则事务B继续正常更新该记录;如果事务A正常提交,无论事务B的更新条件是否仍然生效,都会直接抛出下面的异常:
|
|
用户捕捉到这种异常,可以自行选择是重新开启事务B还是放弃该事务操作。显然,这个就是典型的乐观锁控制并发的方法。
Serializable
在postgreSQL里,这一隔离级别是伪串行化,并不是如上一讲所说的最强封锁协议,即什么都加锁,什么都真正串行处理。但是,postgreSQL这一隔离等级下它的功能表现得与真正的串行化别无二致,用户可以直接认为所有事务都是串行化执行。实际上它的隔离机制与Repeatable read相差无几,无论是快照拍摄的时机还是并发更新冲突的处理都是一样的。唯一的区别便在于前面提到的Serialization Anomaly这一问题。
我们知道Repeatable read在事务开启后的第一个读写操作前拍摄快照,因此在该事务操作里其他事务的结果对当前事务都是毫无影响的。然而,有些业务场景下,事务与事务之间有可能存在依赖关系,我们需要所有事务都是串行化执行的。下面就以官方文档的例子为例,分析一下Serializable在postgreSQL里究竟有何神奇之处:
假设数据库里有一个mytab表:
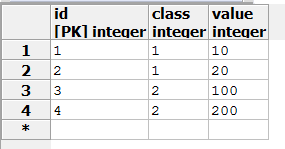
事务A:
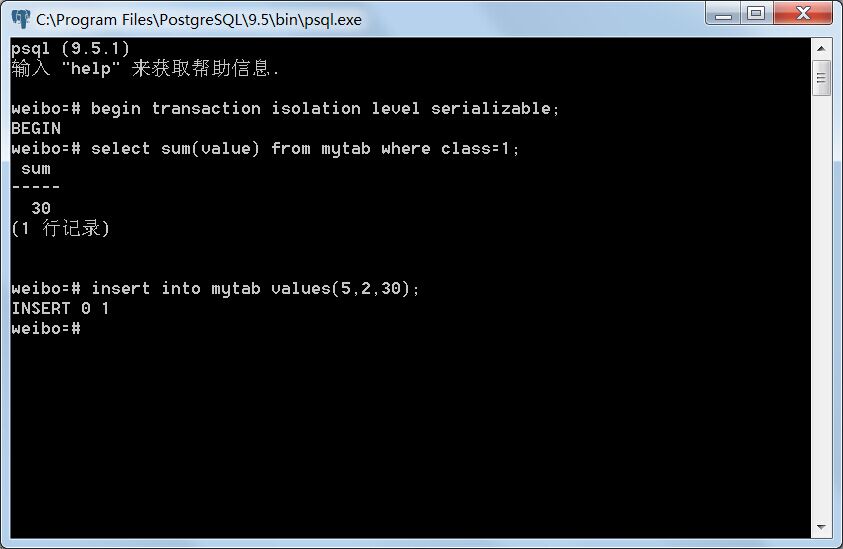
事务B:
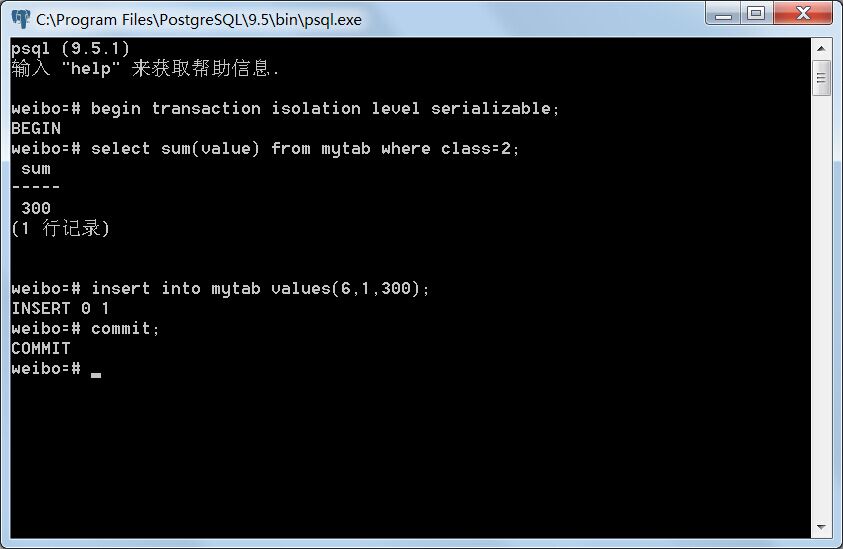
事务A提交:
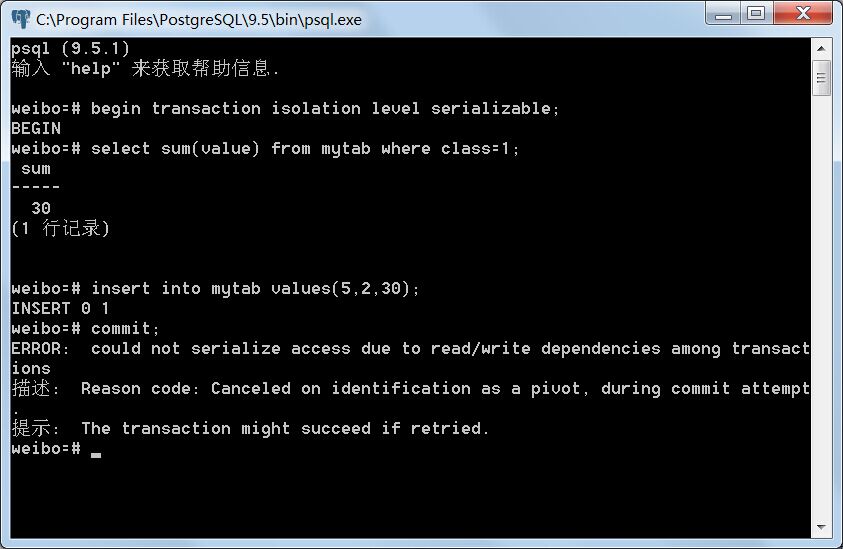
Serializable力图在众多并发事务中寻求一条串行关系,即虽然这些事务是并发执行的,但在所有事务提交以后,如果存在读写依赖关系,可以将它们按先后顺序排序,使得它们表现得宛如串行执行一般。如果这种先后顺序因为并发事务而变得自相矛盾,则会抛出异常。在上面的例子里,事务A对所有class=1的元组的value属性求和,得出30,并将其作为value=30,class=2的元组插入表中;此时,另一个并发事务B对所有class=2的元组的value属性求和,因为两个事务使用的是不同的快照,事务A的修改不会被事务B看到,因此得出300而不是330。这时候,数据库实际上作出了一个假设:即事务B发生在事务A之前,因为事务B读出的值表现得如同是事务A插入数据以前发生的,也即发生了写读依赖。然而,事务B后面再插入了一个value=300,class=1的元组并提交以后,问题就发生了。由于在事务A中对所有class=1的元组的value属性求和时,并没有看到事务B插入的元组,因此数据库作出了另一个假设:即事务B发生在事务A之后,因为事务A读出的值表现得如同是事务B插入数据以前发生,这又是一个写读依赖。
这两个前后的假设显然是矛盾的,所以事务A与事务B违反了串行化要求,所以后提交的事务会抛出异常,此时用户可以选择重启事务或者放弃该事务操作。
MVCC在何处体现
看完上面postgreSQL里三个事务隔离等级的介绍,相信读者大致了解其特点与原理。那么,所谓的MVCC,即多版本并发控制,又是在何处体现呢?显然,就是前面说的“快照”。快照,其实就是相应的版本视图,不同的事务根据事务版本的不同,看到数据库的不同侧面,从而实现读写分离。postgreSQL里快照的抽取十分简单,关键在于两个系统属性:xmin和xmax。下面我将简单分析一下postgreSQL的MVCC实现机制。
MVCC实现机制
在PostgreSQL里,每一个表都默认附加上两个只读的系统属性,xmin和xmax,这两个属性的值共同成为多版本控制的判断条件,所谓快照,实际上就是xmin和xmax满足一定条件的元组集合。
xmin
如果显示地声明了事务,那么每个事务会自动生成一个事务ID作为标识,即txid;如果没有显示声明,那么每一条独立的语句将生成一个事务ID。当进行insert操作时,插入表新增的元组会额外生成一个xmin属性,其值等于当前的事务ID。换言之,元组的xmin属性的值永远等于其插入表时的事务ID。
xmax
当插入元组时,xmax属性默认为0,表示未定义。当对该元组进行update或delete操作时,当前事务ID的值会被赋给xmax。PostgreSQL删除元组不会真的从表里删除数据,而是用xmax>0来标识该元组被删除。而更新元组也不会直接在原来的元组上进行修改,而分为两步进行:第一步是修改原元组的xmax为当前事务ID;第二步是插入一条新的元组,其所有属性值等于原来元组修改过后的值,xmin为当前事务ID,xmax初始化为0。
快照
快照就是某时刻下数据库所有元组的xmin和xmax满足一定条件的值的集合。三个事务隔离等级拍摄快照的时机不同,但其判断条件都是一样的。
总结一下判断条件:
- 若xmin等于当前事务ID,则包含所有xmax=0(未被删除)的元组。
- 若与xmin相等的事务ID对应的事务已经被提交,则包含所有xmax=0或xmax为当前事务ID的元组。
实例
为了帮助读者理解,更好地阐述MVCC的机制,这里设计了一个实例。
初始化准备
建立test表,插入几条数据,如图示:
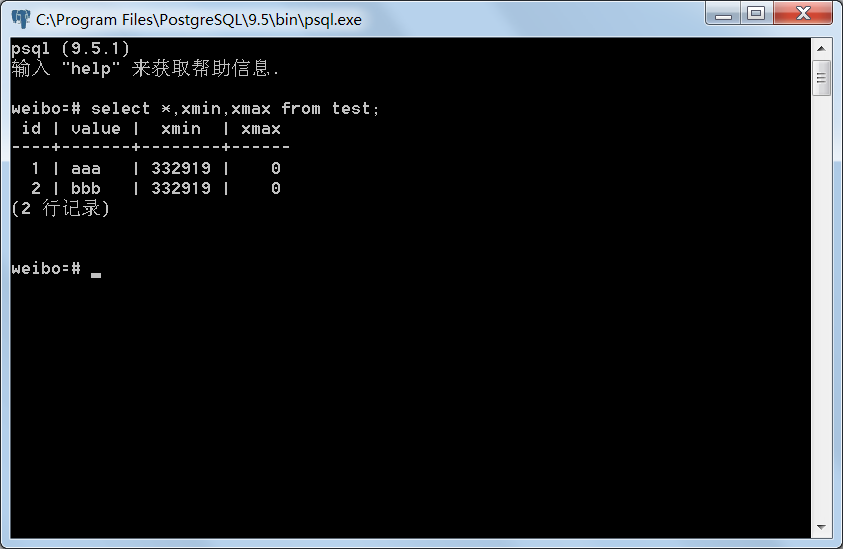
表中插入了两条数据,我们可以读出xmin与xmax的值,由于这两条记录是同一个事务插入的,所以xmin相等,等于该事务ID 332919,xmax为0,表示未定义。
Read commited事务隔离等级下测试
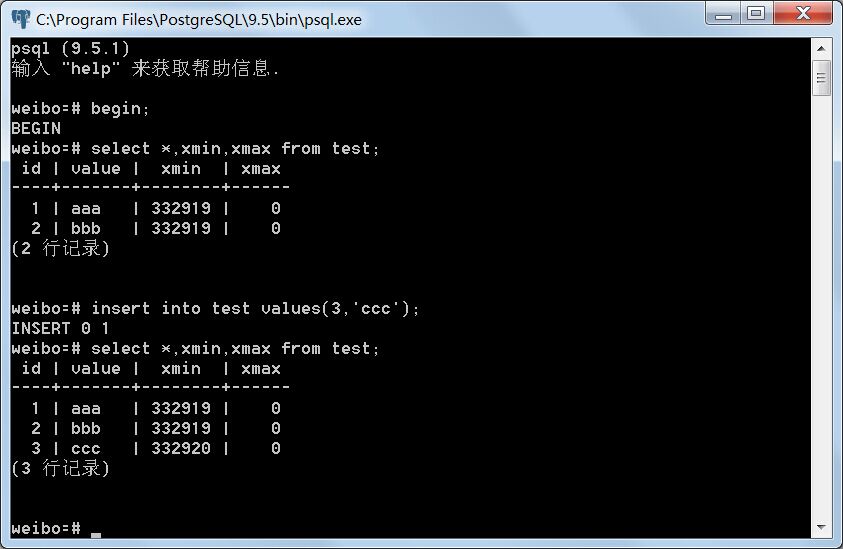
分别开启事务A,B,事务隔离等级取默认的Read commit。事务A向test表插入一条记录,事务A和事务B再分别读取test表,两事务均不提交。
事务A:
事务B:
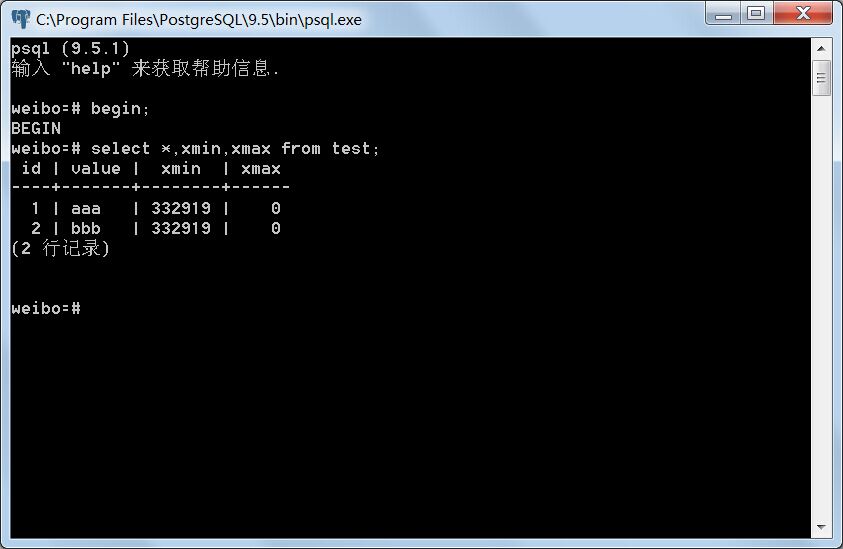
事务A插入元组后,可以看到test表多了一条xmin为332919,xmax为0的新元组。事务B不能看到事务A插入的新元组。
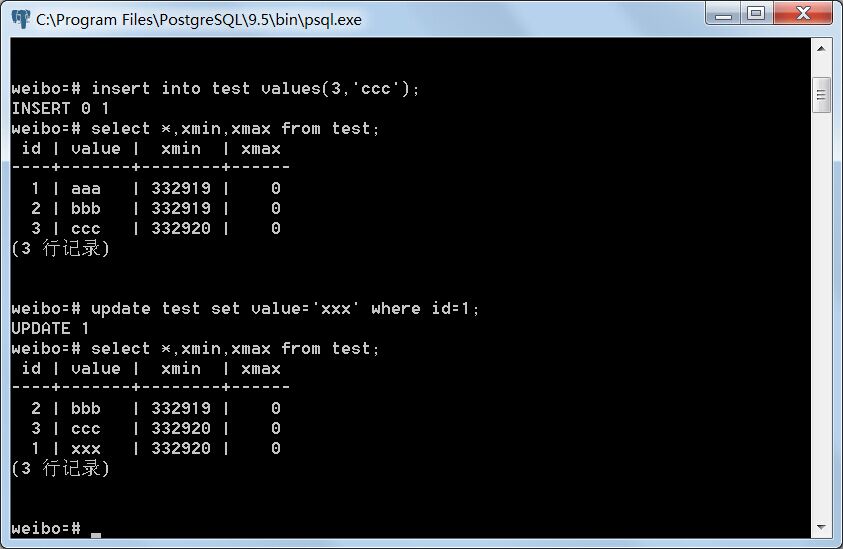
事务A修改id=1的元组,事务A和B分别读取test表,两事务均不提交。
事务A:
事务B:
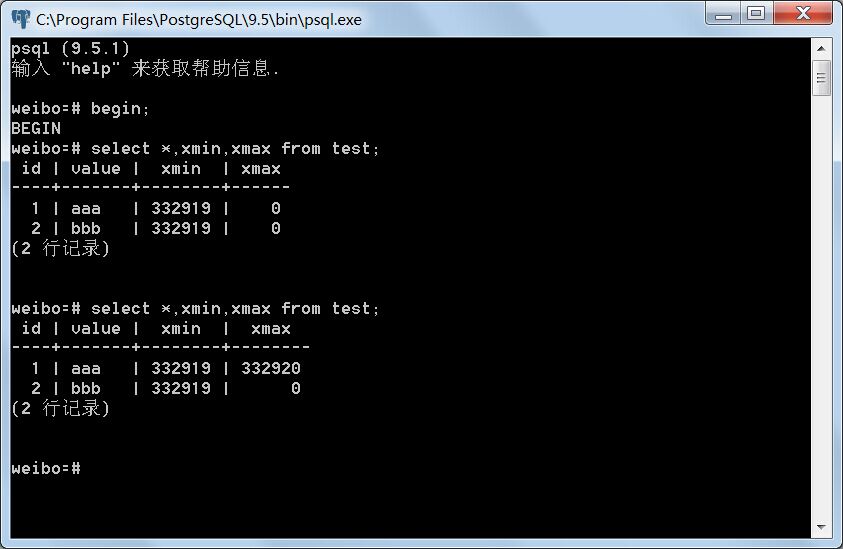
事务A可以看到id为1的元组被修改了,此时它的xmin已经不是332919而是332920;而事务B仍然只能看到id=1的元组的value为aaa,没有改变,只是xmax设为332920。说明事务A看到update操作后新增的那条元组,而看不到原来的那条元组;事务B只看到原来的那条元组,而看不到新增的那条元组。
由此可见,Read commited事务隔离等级下不存在脏读。
事务A提交,事务B再读取test表。
事务A:
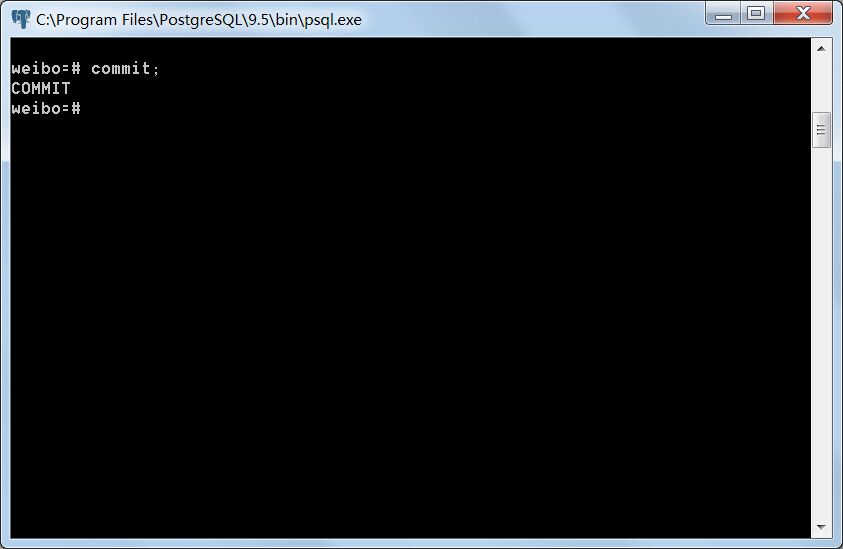
事务B:
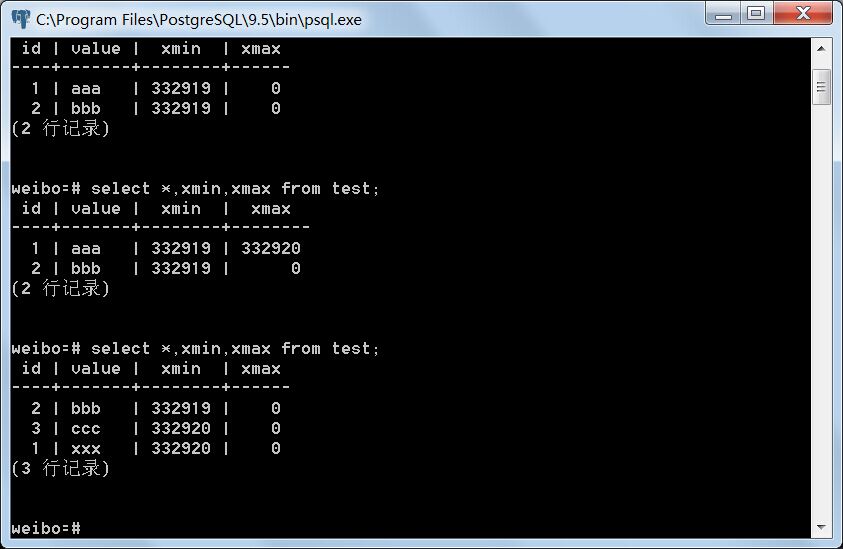
事务A提交以后,事务B读到了事务A新增以及修改的元组。由此可见,Read commited事务隔离等级下存在不可重复读。
Repeatable read事务隔离等级下测试
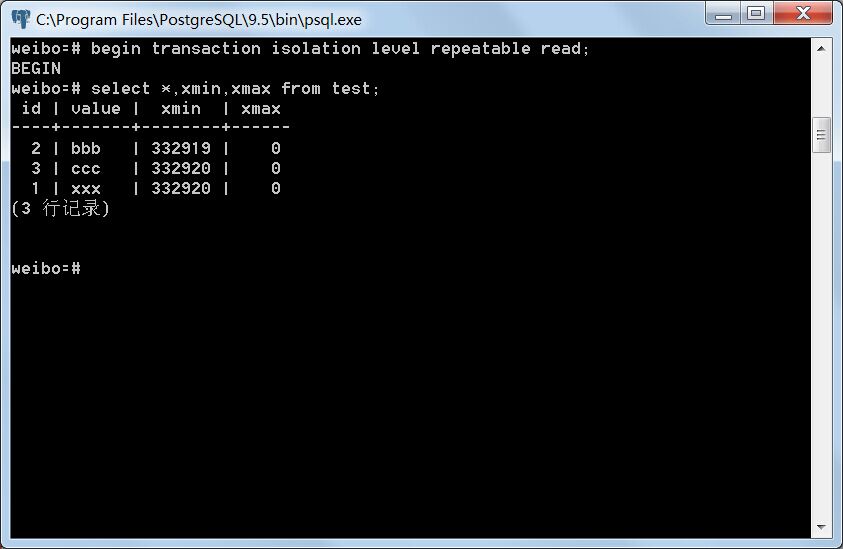
将事务A与事务B提交,重新开启两个事务,其事务隔离等级设为Repeatable read,记为事务C与事务D,分别读取test表。
事务C:
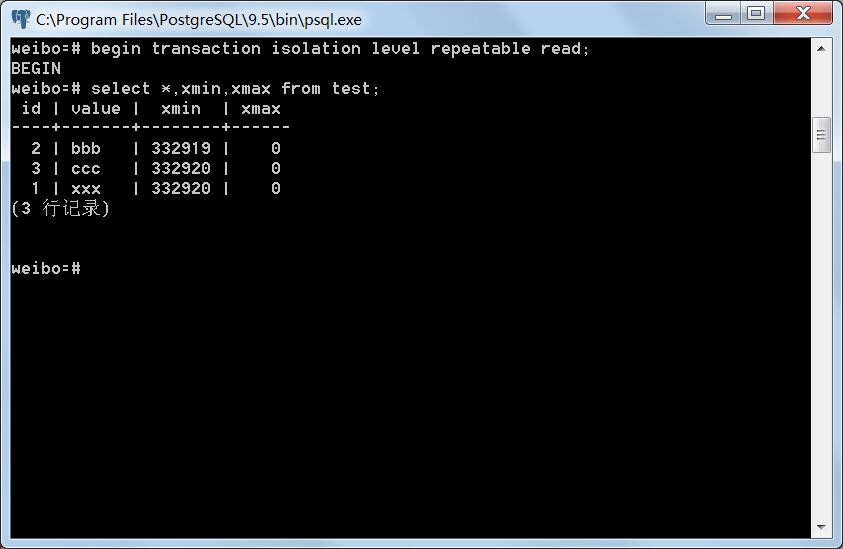
事务D:
事务C修改test表id=2的元组并提交。事务D读取test表。
事务C:
事务D:
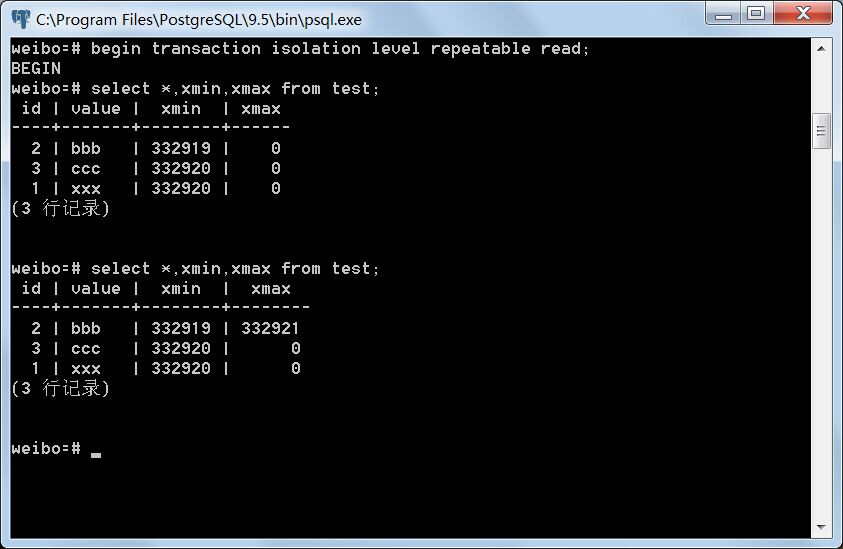
即便事务C提交了,事务D仍然只看到原来未修改前的元组,只是其xmax由0变成332921,即事务C的ID。可见Repeatable read事务隔离等级下不存在不可重复读。
总结
PostgreSQL的MVCC的多版本并发控制技术,用无锁技术控制并发,很好地解决了并发与性能的矛盾,使系统既能够控制并发冲突,又不会因为频繁加锁导致性能恶化。它的快照技术,仅仅通过xmin与xmax两个系统属性简单的判断便可实现,快照的拍摄完全没有时间与空间的消耗。事务的回滚非常方便,仅仅需要修改xmin和xmax属性即可。
但是,这种机制仍然有它的缺点。由于删除并不会真的在表里删除记录,更新操作也是通过插入新记录实现,那么表里会存在许多废旧的记录,占据存储空间,影响查找性能。PostgreSQL里有垃圾清除策略,会维护一个进程专门定期地清理过期的记录,但这个清理周期是不确定的,因此无用的废旧记录仍然会影响数据库的性能。
以上只是PostgeSQL并发控制的一部分知识,关于PostgreSQL的锁机制还有相当多的内容,其MVCC机制里除了xmin与xmax还有cmin与cmax两个系统属性没有涉及。由于篇幅所限,我对这部分理解也不是很足,这里就先不介绍了。以后有机会,我再另外写文章进行讲述。