前言
xv6是x86处理器上用ANSI标准C重新实现的Unix第六版(Unix V6,通常直接被称为V6),本文主要对xv6的shell实现部分的源代码进行分析,同时引申一些操作系统系统调用的内容,包括管道,重定向,进程等等基本概念。通过阅读这部分的源代码,也可以对现代操作系统的shell这个用户程序的核心实现有一个基本的认识。
源代码获得
https://github.com/mit-pdos/xv6-public/blob/master/sh.c 从github上可以获得xv6的源代码,非常精简,不到10000行,其中sh.c文件里就是shell实现的源代码。
总体架构
整体逻辑很清晰,主要就是三部分。入口程序首先做一些预处理,包括命令字符串的过滤和一些系统初始条件的验证。然后对命令字符串进行词法分析,根据命令的类型构造起一个链式的基本命令执行串,其实就是一个链式的自定义结构体。最后是命令的执行阶段,根据构造起的链式结构体串,递归地执行所有基本命令。

预处理器
预处理阶段就在入口函数里处理,逻辑比较简单,主要就是做两件事,一是验证标准输入,标准输出,标准错误是否正常开启;二是对cd命令单独处理。
验证标准输入、标准输出及标准错误正常开启
xv6是用文件描述符来抽象所有的文件、设备、管道等等概念,让它们全都以输入输出流的形式来与用户程序打交道,而掩盖了底层所有与硬件相关的操作。用户程序只需要对相应的文件描述符进行读写操作就行。每个进程都维护一个文件描述表,包含了所有已经打开的文件描述符。默认会开启0,1,2三个描述符,0代表标准输入,1代表标准输出,2代表标准错误。标准输出与标准错误都是输出到屏幕上。因此,shell启动之后第一件事就是验证这三个文件描述符是否正常。
|
|
- open()打开console文件。
- 如果标准输入、标准输出、标准错误都正常工作,那么新的文件描述符肯定大于3,从而得出判断。
- 关闭console文件
利用xv6内核提供给用户的接口–系统调用,来实现打开与关闭某个文件的操作。以上open()和close()就是相应系统调用,除此之外还有一些其他的系统调用,用来处理各种与硬件相关的动作,后面还会介绍其他一些系统调用。xv6的系统调用都是精心设计的接口,也是现代unix系列操作系统的核心系统调用。用户程序会一直在用户空间与内核空间切换。
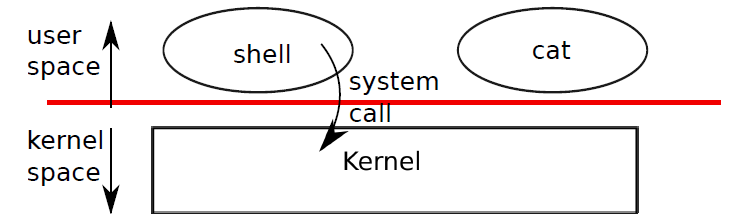
操作系统通过系统调用来连接用户空间与内核空间,从而让不同的用户程序能够共享硬件资源,并对硬件资源作保护,不直接暴露给用户。shell就是这么一个用户程序。
cd
shell中的其他命令都是实现好的用户程序,shell只起到一个转发用户命令,调用实际用户程序这么一个功能,例如cat,rm,cp等等命令。而cd命令必须shell本身实现。
|
|
- shell进程读取标准输入到buf这个字符数组里。
- 判断输入的命令是不是cd。
- 如果是cd,则用系统调用chdir()切换当前进程的工作目录。
- 如果不是,则用系统调用fork(),派生一个子进程。
- 在子进程里进行命令构造与执行。
- 继续读取下一个标准输入的指令。
fork()系统调用会复制父进程的所有内存空间,在该内存空间上创建一个新的进程。由于内存空间完全复制自父进程,那么代码段也自然是一样的,子进程也会执行相同的代码。fork()在父子进程里都会返回,在父进程返回的是子进程的pid;在子进程则返回0。
shell对每一次输入的命令都会派生一个子进程来执行,因此必须在父进程里先处理cd。因为每个进程的工作目录都不同,如果把cd放到子进程中,由外部用户程序来实现,那么只会修改子进程的工作目录,shell本身的工作目录还是得不到改变。
命令构造器
从上面入口函数的代码段可以看到,命令构造实际上就是parsecmd这个函数,接收一个字符指针作为参数,该字符指针指向输入字符串的内存地址。先来看一下shell能够处理哪些命令类型。
命令类型
|
|
共有5种命令类型。
- execcmd,代表最基本的命令,包括命令名与参数,例如
cat y.sh这样的命令。type类型取值范围就是最上面定义的5个宏。argv是参数列表,每个项都是一个字符指针,代表相应的字符串开始的内存位置。eargv的每个项也是一个字符指针,不过与argv相反,它代表的是每个字符串结束的内存位置,主要是作为字符串结束的标志。 - redircmd,代表重定向命令。type的定义与execcmd相同。cmd是子命令,代表实际要执行的命令。file代表重定向的文件名在内存中的其实位置。efile代表文件名在内存中的结束位置。mode代表重定向文件打开的模式,包括只读、只写、读写等等。fd代表重定向要替换的文件描述符,可以取0或1,代表是输入重定向或者是输出重定向。
- pipecmd,代表管道命令。它分成两部分,左命令是提供管道输入的命令,右命令是管道输出的命令。因此包含了两个cmd类型结构体。
- listcmd,代表并列命令。可以把多个命令合成一个命令发送给shell,命令之间以;间隔,shell会分别执行。同样,也包含左右两个命令。例如echo hello; echo world这种形式的命令。
- backcmd,代表后台命令。在命令的最后面加上&,代表放到后台执行。也包含一个实际要执行的cmd命令。
这里面有一个技巧,在命令构造的过程中,用到了递归的链式连接的形式构造命令。因为一个命令可能非常复杂,例如ls < y; ls | sort; who这样的命令,这条命令就可以构造起如下这个链式的命令串:
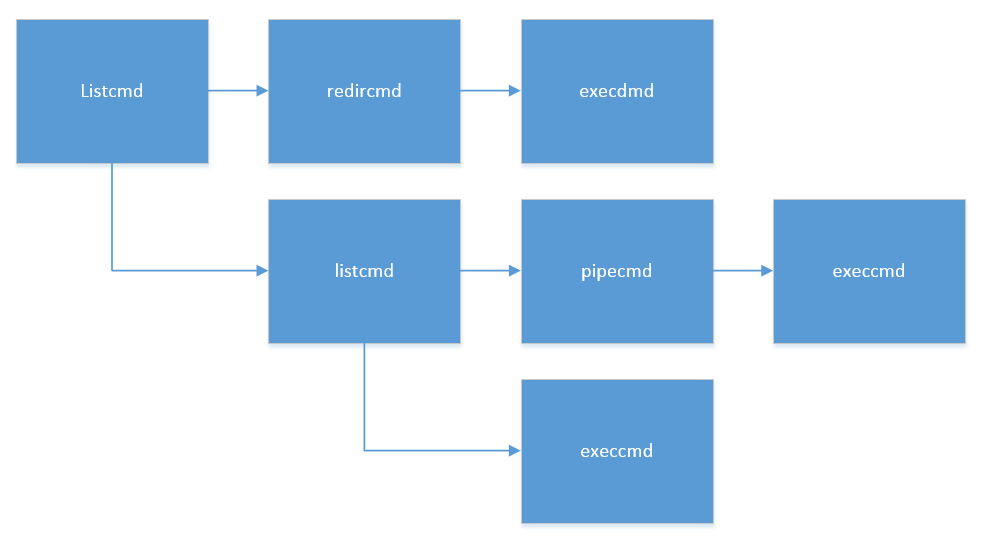
为了统一接口,所有命令类型的子命令都采用了cmd类型,但实际可能是任何一种具体的命令类型。相当于在c语言里使用了类似面向对象的继承与多态的性质,所有的命令类型都继承自一个基础的结构体cmd。它们在实际命令执行的时候再根据type参数向下转型为真正的命令类型。这种技巧使代码变得非常简洁,命令的构造变得统一,构造命令时无需知道子命令是什么,便于递归构造命令串。
命令构造流程
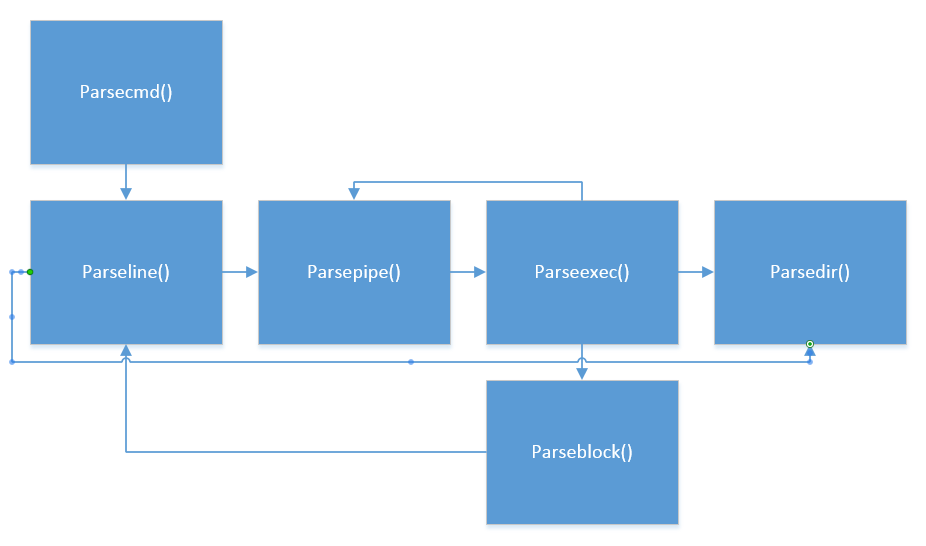
parsecmd()是命令构造函数,它简单地把工作转交给parseline()函数。
parseline顾名思义就是处理一行的输入字符串,把它转化成命令。这一行的概念有点抽象,实际上应该是可以视作一个命令整体的一行字符串,在这行字符串里可以包含各种命令,也就是|&<>();这些字符都可以处理。所有需要处理全部类型字符的工作都可以交给parseline()完成。parseline()里还可以递归地调用parseline()。
parsepipe()用于处理管道命令,由于可能存在多个管道命令,因此parsepipe()可以递归调用自身。
parseblock()处理()内的命令,把()内的命令作为一个整体命令来处理,而忽略从左到右的执行优先级。
parseredirs()用于处理重定向命令,把子命令包裹成redircmd类型。
这些函数通过一连串的互相调用、递归调用,构建起链式的命令串。
parsecmd()
|
|
s就是输入的字符指针,es指向输入字符串的结尾位置。这里主要是把工作转交给parseline(),并在构造完成后判断是否到达输入字符串的末端,否则报错。这里的peek()函数的作用是检查输入字符串从头开始除空格外的第一个字符是否是给定的字符范围中的一个,返回true或者false,同时移动字符指针指向第一个非空格字符。multerminate()是构造命令的最后一步,在后面再介绍。
parseline()
|
|
先以管道为单位划分输入命令字符串,主要的工作都转交给parsepipe()完成。parsepipe()里可以处理<>()这几种字符,而&;则在parseline()里完成,判断是否有并列命令与列表命令。这里处理字符有一个很关键的函数gettoken(),它是一个词法提取函数,用户提取每一个子命令,将在下面一节介绍。在构造listcmd的时候,采用了递归调用自身的方法,这种方式可以解决多个并列命令相连的情况,例如echo hello;echo world;echo haha。
gettoken()
|
|
这个词法提取函数会把一段字符串提取出来,一般是用来提取基本命令或者重定向的文件名。q指向字符串的其实位置,eq指向结尾位置。遇到!();&<>等等则简单地忽略,把指针往后移动到下一个非空格字符;如果遇到实际命令,则返回’a’,代表这是一个真实的基本命令。
前面parseline()里的gettoken()只是简单地把代表并列命令的;以及后台命令的&跳过,让字符指针指向下一个非空格字符,并没有抽取字符串。
parsepipe()
|
|
把命令以|分成两个个子命令,先构造左边的命令,右边的命令则通过递归调用自身来构造。通过递归调用,可以解析多个管道命令相连的情况,例如{block_a} | {block_b} | {block_c} | {block_d}。
parseexec()
|
|
这个函数主要用于构造最基本的命令。如果遇到()的话则把工作转交给parseblock(),否则说明是基本命令,用gettoken()函数把命令字符串提取出来,用q和eq来指定字符串的起始与结束位置,这两个指针将作为execcmd的参数。在解析完基本命令后,很可能还存在着重定向参数,于是把execcmd作为子命令传递给parseredirs()函数,看能不能构造redircmd。
parseblock()
|
|
每一个()里面的命令都可以看作一个整体命令,因此主要是递归地把工作转交给parseline()。只有在parseblock()函数里才能处理)字符,因此最后要判断一下是否存在该字符,否则不是一个完整的block。()内的整体命令可能跟着重定向参数,因此这里也需要用parseredirs()看能不能包装成redircmd。
parseredirs()
|
|
先判断是否有重定向参数,如果没有,则不作任何处理。如果有,则将子命令包装成listcmd。经过gettoken()的词法提取后,q和eq分别指向重定向文件名的起始与结束的内存位置,它们都作为参数构造器listcmd。
nulterminate()
|
|
在parsecmd()函数的最后一步,我们看到调用了nulterminate()这个函数。我们也看到,在execcmd里用eargv数组保存每一个命令参数的字符串结束位置;在redircmd里用efile保存了重定向文件名的字符串结束位置。nulterminate()就是给每一个结束位置指针指向的内存标识上字符串的结束标志\0。让这些参数都成为完整的字符串,那么在命令执行时候就能够正确处理。
命令执行器
在经历了上述的命令构造阶段以后,我们获得了一个封装好的链式命令串,是一个cmd*类型的指针,通过把该指针传递给runcmd(),来执行命令。下面先来看看runcmd()的源代码,然后分析每一种命令是怎么被执行的。
|
|
- 判断cmd的type类型。
- 如果是EXEC,说明是基本命令,用系统调用exec()来执行该命令。基本命令都是一些写好的外部用户程序,以可执行文件的形式来给用户使用。exec()会根据该文件替换掉原进程的所有内存内容,然后执行该程序的代码。这些文件都是以一定的标准格式编写的,需要指定内存的代码区,数据区,堆栈区等等。
- 如果是REDIR,说明是重定向命令。所有用户程序都遵循一个标准,就是用文件描述符0作为输入,文件描述符1作为输出。那么要实现重定向,只需要关闭原来的0或1文件描述符,然后再用系统调用open(),让新打开的文件占用0或1文件描述符,再对子命令递归调用runcmd()函数即可。
- 如果是LIST,说明是并列命令。需要分别执行左右子命令。
- 如果是PIPE,说明是管道命令。也是分别执行左右子命令,对于每个执行子进程,都需要关闭0或1文件描述符,然后用系统调用dup()来让刚刚关闭的文件描述符指向管道某端的文件描述符,从而实现重定向。
- 如果是BACK,说明是后台命令。新派生一个子进程来执行子命令即可。
从上面的命令执行过程可以知道,由于命令构造是用递归实现的,那么执行过程本身也是一个递归过程。通过递归调用,最终形成一个树状的执行链,每一个叶子就是一个基本命令。