前言
最近在项目里面用到了fuse文件系统,在使用过程中遇到了一个内核在做mmap write的一个bug,目前并没有从根本上解决这个bug,而是通过修改fuse kernel module的一些参数,绕开了这个bug。这里记录一下这个问题,并顺便梳理一下fuse在做mmap write的过程,包括如何与项目里的后台服务程序交互的。
背景知识
内存映射
在讲述这个问题之前,先来看看操作系统的mmap操作到底做了什么。
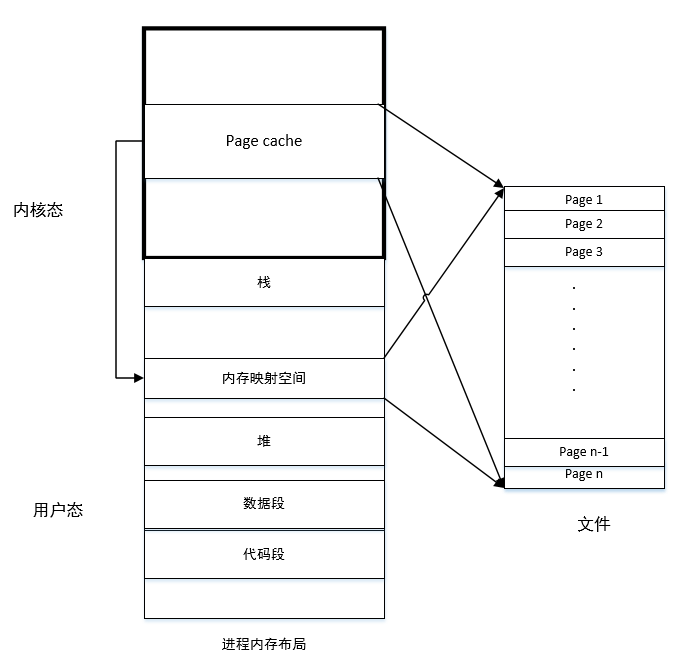
上图是每一个运行时程序(进程)的内存布局,整体上可以分为两大部分,内核态内存和用户态内存,我们平时开发的应用大都运行在用户态,代码、数据、栈、堆,都在内存布局的下方,而内存的上方高字节是内核的代码、数据、栈、堆。重点是内存跟文件的映射部分。内存可以看作是磁盘的缓存,一般的read操作,都会先把数据从磁盘拷贝到内核的page cache部分,以4KB页为单位缓存磁盘页,然后再从page cache拷贝到用户态内存的堆或栈里分配的buffer中;一般的写操作,则从用户态内存的堆或栈里分配的buffer中,先拷贝到page cache,最后再异步地写到磁盘里。之所以这里有内存的两次拷贝,是因为内核空间是映射到每个用户进程的虚拟内存里的,而用户态内存大部分情况下是进程独立的,为了每个进程都能用到文件缓存,所以Page cache要放到内核空间,所以存在着两次拷贝的性能损耗。
针对这个两次拷贝的性能损失,操作系统提供了mmap这么一个对大文件读写性能优化的手段。mmap能够让用户态的某段内存与文件的某段数据建立映射关系,对于使用者来说,不需要用write,read这两个对文件读写的接口,而是可以用memcpy和memset对内存操作的接口,通过直接读写内存来修改和读取文件内容。mmap最大的优点是:由于它同样用page与文件一一映射了,与page cache有异曲同工之妙,所以能够与page cache直接关联起来,去掉了两次拷贝的操作,读写仍然是磁盘和page cache之间,但内存映射区域可以直接使用page cache,免去了内核态与用户态之间的拷贝。
mmap有它的缺陷:
- 内存映射以后,不能调整空间大小,就是说文件大小要固定,只能有修改操作,不能有追加操作。一般来说是用于预先知道文件大小的场景,先用truncate预分配空间,然后mmap映射到内存。
- 初始化mmap开销较大,小文件读写比不上直接用read,write调用,适合大文件或者需要频繁读写同一段数据的场景。
fuse网络文件系统架构
一般的文件系统都是运行在内核态的(xfs,ext4,ext3,ext2…),程序遵循用户态->内核态->用户态这么一个状态切换,以mmap write操作为例,用户态程序用memcpy这个c库函数,发现拷贝的区域是内存映射区域,会陷入内核态,数据从用户态拷贝到page cache里,并把相应page标记为dirty,等待合适的时候再真正写到磁盘或者网络上,然后内核马上返回用户态,给用户返回写的结果。
我们项目里用到的fuse文件系统,是一个用户态文件系统,可想而知性能比较差一点,但胜在开发门槛较低。使用fuse操作文件,程序遵循用户态->内核态->用户态->内核态->用户态这么一个状态切换。
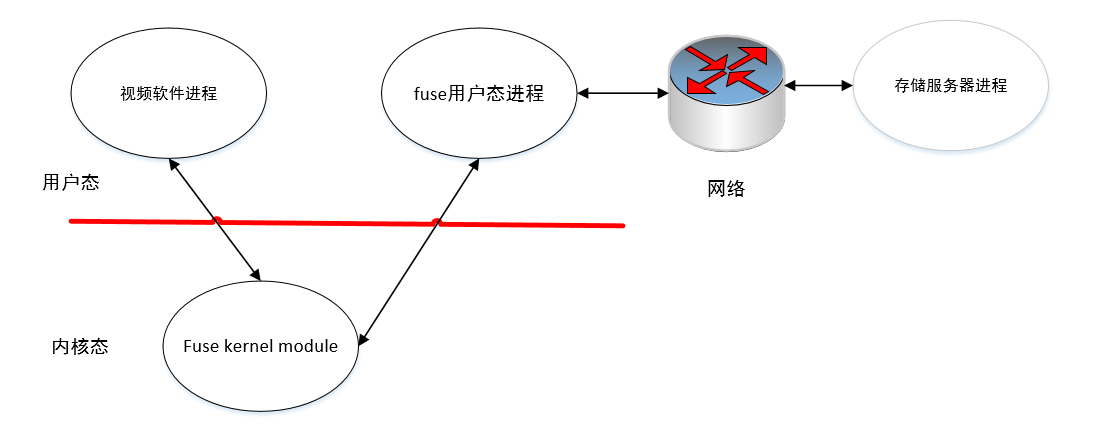
上图展示了我们项目的客户端部分的系统架构。 需要读写操作的第三方软件程序发起读写请求,陷入内核态,fuse有一个kernel module扮演生产者的角色,接收请求,并封装好请求数据,写到一个字符设备上,并唤醒用户态的fuse进程。 用户态fuse进程作为消费者检测字符设备上是否有请求到达,接收请求,通过socket发到网络上。 实际的读写操作由服务器进程处理,并把结果走socket返回给fuse用户态进程。fuse用户态进程接到响应后,把返回数据封装好写到字符设备上,并唤醒内核。fuse kernel module被唤醒后,从字符设备上读取数据,解析后返回给第三方软件。
fuse mmap write 性能问题
现象
某不知名第三方视频软件与我们的系统对接,把我们系统作为存储后端做视频存储。该软件在启动时候需要mmap一个或多个10MB的索引文件,然后读一部分数据出来,再写一部分数据回去。这个过程如果mmap的是本地文件系统(xfs),每个索引文件读写包括计算大概需要10~20ms。但接上了fuse文件系统后,有一定概率会出现mmap阻塞,这个mmap读写过程需要3分钟甚至更长!这样的话,一旦索引文件多起来(每1GB的视频文件需要10MB的索引文件),启动速度就变得不可接受了。
首先,我们排除掉了后台服务程序的问题,通过客户端的日志,发现每一个请求都是马上返回,但每个请求与请求之间有几秒的间隙,所以肯定是上层调用出了问题。
然后,我们排除了fuse用户态程序的问题。第一,我们先尝试用fuse官方的passthrough程序来做同样的mmap测试,发现仍然存在这个问题,基本排除是用户态的问题。第二,前面说到,用户态fuse进程是作为消费者,等待字符设备的数据到达。通过分析日志,发现字符设备上每个到达请求之间有几秒的间隙,所以确定问题是出在生产者fuse kernel module身上。
通过trace内核的执行,我们最终发现,罪魁祸首就在balance_dirty_pages()函数内,以下是trace的日志:
|
|
balance_dirty_pages是控制什么时候触发写回的一个手段,可见问题出在page cache write back上。 从trace log中发现,每次调用balance_dirty_pages都会消耗85ms左右的时间,而这个balance_dirty_pages会反复调用,并且都消耗大量的时间,推测是因为每次调用完了之后,并没有实际把脏页写回,所以balance_dirty_pages_ratelimited的判断每次都会成立。后面看一看内核的write back实现细节是怎么样的。
write back 过程
fuse mmap write是采用了其他文件系统常用的write back机制,就是写page cache成功以后,把page标记为dirty,直接返回,实际的写操作是由内核异步完成。write back机制是每个文件系统独立完成,一般情况下由以下条件触发:
- 页面Cache变得太满,并且还需要更多的内存页,或者脏页的数量非常大;
- 脏页停留在内存中的时间过长;
- 某个进程要求更改的块设备或某个文件数据刷新,通常调用sync系统来实现。
文件系统控制写回的数据结构–bdi设备
bdi是backing device info的缩写,每一个文件系统在内核里都维护这么一个结构,管理实际的write back。fuse内核模块在初始化的时候,会注册一个bdi。
|
|
这里面fuse在注册bdi的时候,会启动一个线程,这个线程执行bdi_writeback_workfn函数,实际的write back操作由这个函数完成。下图给出bdi处理write back用到的主要数据结构及关系:
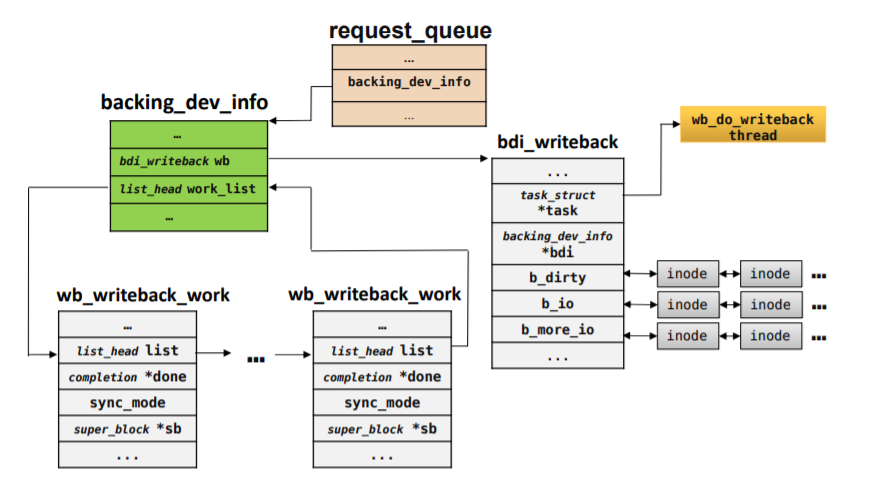
注意一下上面那个BDI_CAP_STRICTLIMIT属性,这个属性造成了这次的bug。如果把这个属性去掉,则性能问题消失。
周期性检查write back
内核在内存紧张的时候是可以进行cache替换,把已经写回的page cache回收分配给其他用途,但这个page必须没有加上dirty或者wrieteback的标志位。为了防止进程短时间内制造大量脏页占用过量内存,linux会在linux每次写ratelimit_pages这么多的mmap内存以后,会调用以下函数,检查是否需要写回一部分脏页:
|
|
重点看一下current->nr_dirtied >= ratelimit这句,当当前写进程的脏页达到一个限制时,会调用balance_dirty_pages()函数,从而造成写进程阻塞,避免生成大量脏页占用大量内存。
balance_dirty_pages
balance_dirty_pages的逻辑有点复杂,只抽取重点部分看一下:
|
|
这个判断条件里有没有strict_limit是不同的情况,之前看到fuse设置了strict_limit,那么检查脏页的时候就主要是受fuse本身的脏页限制,否则按照linux内核的限制。当满足限制的时候则调用bdi_start_background_writeback,这个函数会唤醒之前说的真正处理writeback的线程,执行bdi_writeback_workfn函数。
bdi_writeback_workfn最终会调用fuse自定义的fuse_writepage函数把具体的写回任务交给fuse,然后fuse再把任务交给我们的存储服务器。
fuse_writepage
每一个脏页的写回,都会调用这个函数。主要关注一下page的状态变化。
|
|
set_page_writeback取消page的dirty标记,打上writeback标记。- fuse会向内核内存资源池申请一个4KB的新页。
copy_highpage将原page的内容拷贝到新page。inc_bdi_stat(mapping->backing_dev_info, BDI_WRITEBACK)给bdi自身的写回计数器加1,inc_zone_page_state(tmp_page, NR_WRITEBACK_TEMP)会同时把该页的计数放到内核全局的NR_WRITEBACK_TEMP计数器里,正常情况应该是放到NR_WRITEBACK计数器里,否则如果不设置striclimit的话,内核是不会把该页统计为脏页的。- 封装req数据,发送到字符设备,并唤醒用户态fuse进程。
- 取消旧page的writeback标记。
从上面函数可以看到fuse自己管理要写回的脏页,旧的由内核管理的脏页马上标记成已经写回成功了。这样内核的脏页计数就不会把该页和新页统计在里面,如果fuse的设置去掉了strict_limit标志以后,脏页就没有任何控制了。
目前解决办法
取消掉了strict_limit标记,但由于fuse在写回的时候选择异步的方式,把旧页直接清除掉writeback标记返回,真正的写回是用一个新页来完成,如果单纯取消strict_limit,那么fuse的脏页就既不由fuse控制又不受内核全局控制。目前的办法是把fuse_writepage_locked函数的inc_zone_page_state(tmp_page, NR_WRITEBACK_TEMP)改成inc_zone_page_state(tmp_page, NR_WRITEBACK)。