前言
erlang作为函数式与天生并发的语言,其内存管理与垃圾回收无疑便是重点话题。本文并不想详细解析其内存管理与垃圾回收机制,而关注的是与这个主题密切相关的二进制串型。二进制串型是erlang的一种数据类型,目的是用二进制数编码erlang的其他类型,通常是用做进程间的大数据量传输。其设计非常精妙,特别是erlang的R12B版本以后对其做了大幅度的优化,有必要分析一下它对于erlang内存管理方面的影响。
erlang的内存管理模型
具体展开分析二进制串型之前,先来看看erlang的内存管理模型
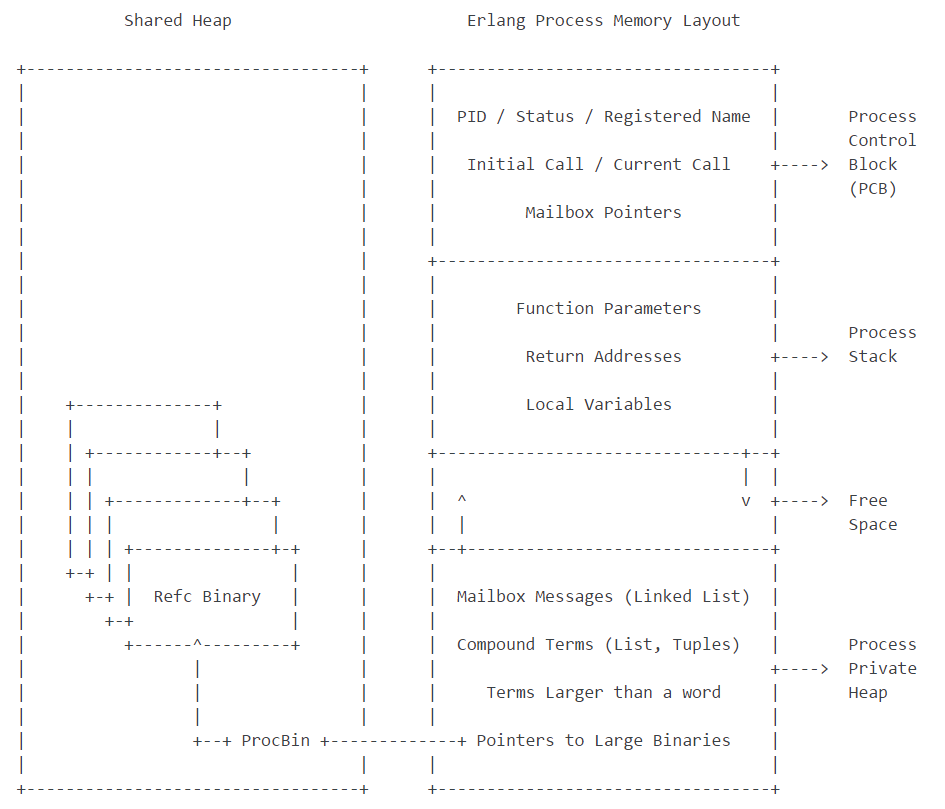
这幅图是erlang比较经典的介绍内存管理的结构图。可以看到其内存可以大致分成4个区域。
- 进程控制块。存储进程的一些元数据信息,例如进程PID,状态,注册名字等等。
- 栈。存储一些函数参数,本地参数等小于一个机器字的轻量数据。
- 堆。进程的主要存储区,存储进程的消息队列,复杂的数据,例如列表,元组,二进制串等等。
- 共享区域。所有进程共享的内存区,主要存储refc binary。
这里不做过多展开,只需要注意两部分,就是堆中的二进制串与共享区域的refc binary。erlang的内存是分进程管理的,每个进程有自己的堆,绝大部分数据都存储在独立的进程堆中,进程间的消息通信一般不存在内存共享,都是采用复制式通信。这就包括所有小于64字节的二进制串型。但这种复制式通信有一个例外,就是大于64字节的二进制串型,如果全都采用复制式通信,会造成极大的内存与时间的消耗,因此把这些二进制串放在共享区域中,称为refc binary。
所有的refc binary都有一个元数据指针,称作ProcBin。它直接指向共享内存区的refc binary数据块,并且还包含了一些非常重要的元数据。当要在进程间传输refc binary时,不复制真正的数据块,而是把ProcBin复制一份,传送到其他进程。当然这个得在同一个erlang node中,否则还是会复制真正的数据块。
4种类型的erlang二进制串
初步认识了refc binary,知道了erlang二进制串虽然在开发人员看来只有一种数据类型,但其内部是分为不只一种的。其实内部实现共有4种,本文就是对这4种类型展开阐述。
heap binary
堆二进制串。所有小于64字节的二进制串型都作为进程私有堆中的数据存储。
refc binary
引用二进制串型。这种类型分为两部分,一部分是在共享区域中的真正数据,另一部分是在进程堆中的ProcBin指针。ProcBin还包含了数据块的实际大小信息。
sub binary
子二进制串。对于一个长串的二进制串,在数据处理时候经常需要匹配其中的一小部分。为了在时间与空间上更加轻量与廉价,对于子二进制串是不会复制再另外分配内存的,一般只是生成一个引用指向该原数据,该引用包含在原数据块中的大小与偏移量。
match context
匹配上下文。一般用在二进制串的模式匹配中,用于对子二进制串的优化。它维护一个指针直接指向原数据块,在绝非必要的情况下不会生成子二进制串。erlang R12B版本之后关于用match context进行子二进制串优化做了很多工作,会在后面阐述。
构造二进制串
R12B版本之后,构造二进制串有了大幅度的优化。
优化原理
在创建二进制串时,我们往往是采用分段拼接的方法。例如:
|
|
erlang虚拟机会把Bin0作为heap binary在进程堆空间中分配内存。那么Bin1呢,是否会把Bin0复制一份再加上后面3个整数?Bin2呢?答案是,前者是肯定,后者是否定的。为了让构造二进制串更加轻量与廉价,在构造Bin1时,会把Bin0复制,生成一个refc binary,在后面接上<<1, 2, 3>>。但是,Bin1还会扩展内存,在实际数据后面加入一段空余空间。如果原数据的2倍小于256字节则refc binary会扩充空余空间直到256字节,否则扩充到原数据大小的2倍。这里,Bin1的有用数据大小是4字节,因此会扩充到256字节。因此,Bin1会分配256字节空间到共享内存区域,其ProcBin在进程私有堆空间中,保存了实际大小4字节的信息。在构造Bin2时,则会直接在空余空间中写入<<4, 5, 6>>。
此后,如果再向Bin2后面添加数据,只要数据块总大小不超过256字节,就直接在空余空间中写入,不会有复制动作。如果添加的数据耗尽了所有空余空间,则会重新分配内存,继续扩充空间到实际数据大小的2倍。
例外情况
还是有一些例外情况,使得构造二进制串必须采用复制,而不能直接在后面拼接。
仍然是之前的例子。
|
|
Bin2和Bin3都是直接在空余空间中写入后续数据的,但Bin4不一样。Bin4是在Bin1后面写入,但我们知道,在构造了Bin2和Bin3之后,Bin1对应的数据块后面已经紧跟了<<4, 5, 6, 7, 8, 9>>。erlang具有函数式语言的引用透明性的特点,不能让Bin4在Bin1后面写入数据,否则会覆盖掉4,使得数据块变成<<0, 1, 2, 3, 17, 5, 6, 7, 8, 9>>。这时候,会对Bin1进行复制,在后面拼接17,并且重新分配空余空间。这种情况下复制是合理的,且是必须的。
另一种情况,是如果要把refc binary作为进程间消息进行传递,后续再进行拼接时必须对原数据进行复制。
|
|
Bin1发送给别的进程或者端口,这时候会触发原数据块的收缩,把空余空间全部砍掉,再复制ProcBin,发送给端口或者进程。
后续通过Bin1构造Bin时,则会复制一份Bin1,再分配空余空间,形成新的refc binary。
还有一种情况,是对refc binary进行模式匹配后,会触发原数据块的收缩,后续的拼接也会强制进行复制。
|
|
最后,当进程长期持有某个refc binary时,垃圾回收器会对它进行收缩处理。如果之后要进行拼接,则会重新分配内存,在后面添加空余空间。
二进制串匹配
R12B对二进制串匹配做了大量的优化。
match context如何工作
先来看看match context是如何工作的。
|
|
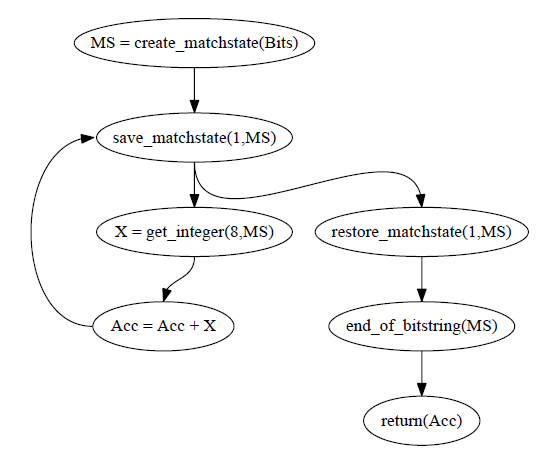
erlang编译器会对这段代码展开,生成处理模式匹配的代码,下面看看生成的代码流程图:
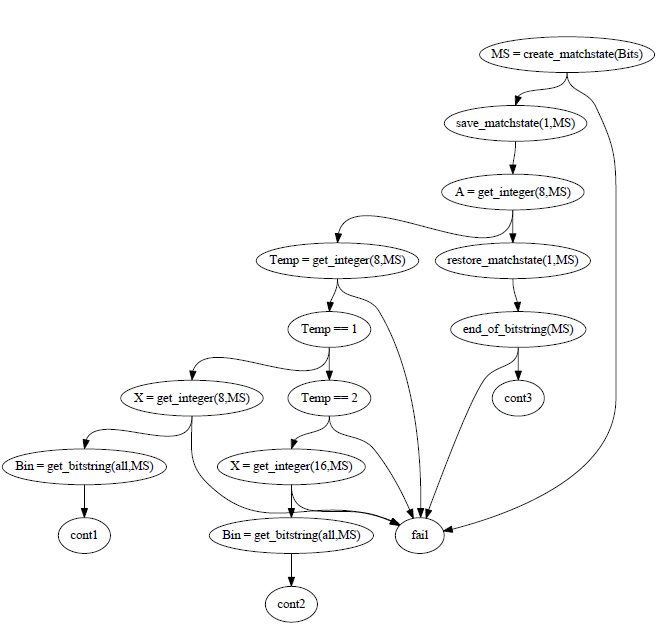
先来看看里面涉及到的几个函数:
- create_matchstate。这个函数会对传入的二进制串生成match context,一开始指向第一个字节。
- save_matchstate会存储当前的match context,以便将来恢复出二进制串。
- get_integer会根据match context以及附加偏移量从二进制串中提取一个整型数据,并且更新match context的偏移量。
- get_bitstring会根据match context生成sub binary。
- restore_matchstate会根据之前save_matchstate存储的二进制串恢复当时的match context偏移量。
- 判断match context的偏移量是否等于二进制串的总长度,从而知道是否已经不能再匹配了。
上述代码的整个匹配流程如下:
- 对Bits这个变量调用create_matchstate,生成match context。
- 存储刚刚生成的match context。
- 对match context调用get_integer,传入偏移量8,生成integer作为变量A的值,并且更新match context,使其指向下一个字节。如果能得到整型,则进入左分支。否则调用restore_matchstate,恢复之前存储的match context,再调用end_of_bitstring判断是否已经到达二进制串的末尾,如果是,则原代码case语句匹配到最后一个子句,返回cont3。
- 如果进入左分支,再调用get_integer,传入偏移量8,生成integer,并更新match context。如果生成的整数是1,则进入下一个左分支;如果是2,则进入右分支。
- 如果进入下一个左分支,则再调用get_integer,传入偏移量8,生成integer作为变量X的值,更新match context,使其继续指向下一个字节。然后,对更新后的match context调用get_bitstring,把剩余的所有二进制串都传入,生成一个sub binary。此时,对应到原代码的子句一,返回cont1。
- 如果进入右分支,则调用get_integer,传入偏移量16,生成integer作为变量X的值,更新match context,使其指向后两个字节。然后,对更新后的match context调用get_bitstring,把剩余的所有二进制串都传入,生成一个sub binary。此时,对应到原代码的子句二,返回cont2。
R11B前的二进制串匹配
先来看看R12B前,erlang对二进制串的处理有哪些性能不理想的地方,以及如何对其优化。
|
|
在R11B时,sum1/2函数的效率是很低的。来看看由上述sum1/2函数生成的内部代码流程图:
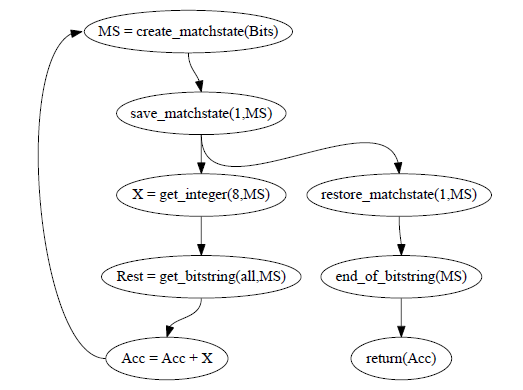
再每次递归调用时,都会生成一个match context和一个sub binary。这个sub binary在下一次递归调用时只用来生成下一个match context,而并没有其他作用。这样在N次递归调用后,会生成N个sub binary以及N+1个match context。
在R12B前,可以用sum2/3函数来优化这个累加的过程。来看看sum2/3函数生成的内部代码流程图:
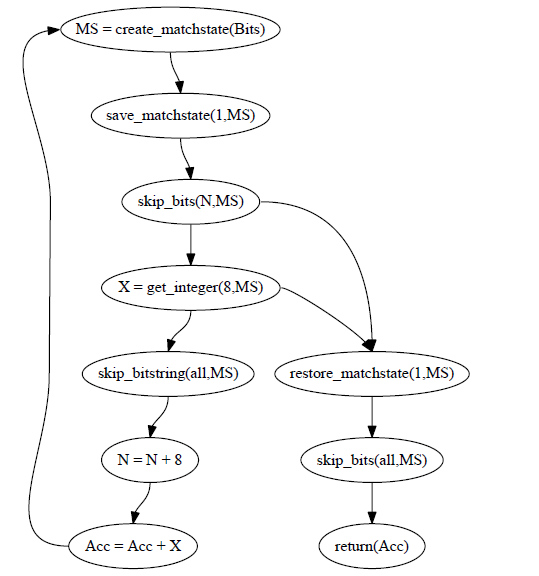
sum2/3函数自己维护一个偏移量N,而不把Rest传递给下一个递归调用。这样就不会由match context生成sub binary。但是每次递归调用仍然会创建一个match context。N次递归调用后,仍然会生成N+1个match context。
R12B的二进制匹配优化
R12B提供了对match context延迟生成sub binary的优化,看看sum1/2函数优化后的内部代码流程图:
erlang编译器会自动检测Rest是否会被用作其他用途,如果单纯只是用在下一个递归中,则不会生成sub binary,也不会在每次递归调用中生成match context,会一直保存match context,并把match context传给下一个递归调用。直到当编译器发现要传进来的二进制串及match context需要用作其他用途,例如传递给除自身递归函数以外的函数,则会延迟生成一个sub binary。
这样,N次递归调用只会生成一个match context。
编译器无法优化
前面说到,只有当erlang编译器能明确知道match context不需要用作其他用途,才不会生成sub binary。但有些时候,编译器比较笨,使得优化失败。但我们不需要自己判断什么时候无法优化,而可以利用erlang的输出信息来检测。
第一个方法,是在编译时候加入bin_opt_info参数。
|
|
还可以修改环境变量。
|
|
这样,在涉及到编译器无法优化或者可以优化二进制串匹配时候,就会输出日志信息。
|
|
并且,除了warning信息以外,如果无法优化,还会有相应的info信息告诉你为什么无法优化,需要怎么调整代码。
总结
根据以上几点R12B对二进制串的优化,我们写代码时候可以注意一下几点:
- 在进行二进制串构造时,把原二进制串放在前面,附加数据放在后面,这样可以利用空余空间,而不需要进行内存复制。
- 在递归处理二进制串匹配时,注意除了自身递归调用函数以外,不要在其他地方共享match context。这样就会延迟生成sub binary。